Introduction
SeaORM is a feature rich async ORM for integrating a Rust code base with relational databases aiming to be a write code once and run on any popular Relational Database with current support for MySQL, PostgreSQL, MariaDB and SQLite. The tutorials in this book are a gentle introduction to using the sea-orm crate and its cli tool sea-orm-cli.
Symbols Used
Some symbols used throughout this book make it easier to visualize changes to a file.
To show added or removed code from files, we will use comments or
+ to show added code
- to show removed code
... is used to show only part of the existing code instead of rewriting already existing code in the examples
$ shows an operation is done on the console/shell
Chapters
In the first chapter, we will learn how to build a backend application with SeaORM. It will be compatible with different database implementations.
In the subsequent chapters, we will explore the process of building other applications that integrate with a SeaORM-powered backend. In particular, we will be looking at how to build Rocket and GraphQL applications that interact with the backend we created in the first chapter.
Let's get started.
Chapter 1 - Building a Backend with SeaORM
Full source code available on GitHub.
In this chapter, we will build a backend application with SeaORM. It will act as a layer of communication with the database.
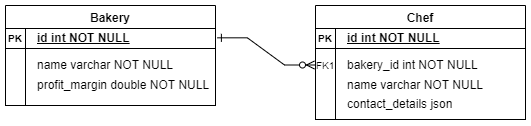
The application will simulate the interface of a database of bakeries. For simplicity, there will be only two entities, Bakery and Chef. We will explore the schema later on.
Choosing a Database
Before we start building the backend, we want to make sure that the database is up and running. Setting up the database is beyond the scope of this tutorial.
SeaORM itself is agnostic to different database implementations, including MySQL, PostgreSQL, and SQLite (in files or in memory).
However, depending on the database of your choice, you need to pay attention to the following:
- The appropriate DB driver feature should be enabled.
- A valid database URL should be used:
| Database | Example Database URL |
|---|---|
| MySQL | mysql://root:root@localhost:3306 |
| PostgreSQL | postgres://root:root@localhost:5432 |
| SQLite (in file) | sqlite:./sqlite.db?mode=rwc |
| SQLite (in memory) | sqlite::memory: |
We will showcase exactly how to and where to use them in the next section.
Once the database is ready, we can proceed to set up the project.
Project Setup
In this section, we will set up our project, including the folder structure and crate dependencies.
We will be using a MySQL database throughout the tutorials, but all functionalities of SeaORM are agnostic to the database implementation, as mentioned before.
Adding sea-orm as a Dependency
$ cargo init bakery-backend
# Cargo.toml
...
[dependencies]
+ sea-orm = { version = "^0.12.0", features = [ "sqlx-mysql", "runtime-async-std-native-tls", "macros" ] }
...
The DB driver feature sqlx-mysql is used because we are using MySQL.
The second feature, runtime-async-std-native-tls is an async runtime arbitrarily chosen for this project. More information can be found on the docs.
Finally, the macros feature is an optional feature that allows the use of some Derive macros.
Connecting to the Database server
We add futures as a dependency so that we can make use of asynchronous programming with async/await.
# Cargo.toml
...
[dependencies]
+ futures = "0.3.28"
sea-orm = { version = "^0.12.0", features = [ "sqlx-mysql", "runtime-async-std-native-tls", "macros" ] }
...
Connect to the database server:
// main.rs use futures::executor::block_on; use sea_orm::{Database, DbErr}; // Change this according to your database implementation, // or supply it as an environment variable. // the whole database URL string follows the following format: // "protocol://username:password@host:port/database" // We put the database name (that last bit) in a separate variable simply for convenience. const DATABASE_URL: &str = "mysql://root:root@localhost:3306"; const DB_NAME: &str = "bakeries_db"; async fn run() -> Result<(), DbErr> { let db = Database::connect(DATABASE_URL).await?; Ok(()) } fn main() { if let Err(err) = block_on(run()) { panic!("{}", err); } }
If everything is correctly set up, the program should terminate gracefully.
If it panicks, it could be that the database URL is wrong.
If it hangs, it could be that the database is not up and running.
Creating a Database
For MySQL and PostgreSQL, we can create a specific database instance. Let's call it bakeries_db.
#![allow(unused)] fn main() { ... // main.rs - use sea_orm::{Database, DbErr}; + use sea_orm::{ConnectionTrait, Database, DbBackend, DbErr, Statement}; ... async fn run() -> Result<(), DbErr> { let db = Database::connect(DATABASE_URL).await?; + let db = &match db.get_database_backend() { + DbBackend::MySql => { + db.execute(Statement::from_string( + db.get_database_backend(), + format!("CREATE DATABASE IF NOT EXISTS `{}`;", DB_NAME), + )) + .await?; + + let url = format!("{}/{}", DATABASE_URL, DB_NAME); + Database::connect(&url).await? + } + DbBackend::Postgres => { + db.execute(Statement::from_string( + db.get_database_backend(), + format!("DROP DATABASE IF EXISTS \"{}\";", DB_NAME), + )) + .await?; + db.execute(Statement::from_string( + db.get_database_backend(), + format!("CREATE DATABASE \"{}\";", DB_NAME), + )) + .await?; + + let url = format!("{}/{}", DATABASE_URL, DB_NAME); + Database::connect(&url).await? + } + DbBackend::Sqlite => db, + }; Ok(()) } ... }
This snippet shows that SeaORM is database-agnostic. You may only handle the case for your chosen database if you are sure only one type of database will be used.
Migration (CLI)
This and the next sections concern those who are getting a taste of SeaORM by creating a new, toy database schema. If you already have an existing database schema, feel free to skip over to Section 1.4.
In this section, we define the following simple schema with migrations.
Initialize using sea-orm-cli
For beginners, it is recommended to use sea-orm-cli to define and run the migrations.
# Install `sea-orm-cli`
$ cargo install sea-orm-cli
# List all available migration commands that are supported by `sea-orm-cli`
$ sea-orm-cli migrate -h
Initialize the migration folder:
$ sea-orm-cli migrate init
# The folder structure will be as follows:
.
├── Cargo.toml
├── migration
│ ├── Cargo.toml
│ ├── README.md
│ └── src
│ ├── lib.rs
│ ├── m20220101_000001_create_table.rs
│ └── main.rs
└── src
└── main.rs
Define the migrations
Update the migration files to define the Bakery and Chef tables:
The filename must follow the format m<date>_<6-digit-index>_<description>.rs.
For more information about defining migrations, read the documentation of SchemaManager.
- m20220101_000001_create_table.rs
+ m20220101_000001_create_bakery_table.rs
+ m20220101_000002_create_chef_table.rs
#![allow(unused)] fn main() { // m20220101_000001_create_bakery_table.rs use sea_orm_migration::prelude::*; pub struct Migration; impl MigrationName for Migration { fn name(&self) -> &str { "m20220101_000001_create_bakery_table" // Make sure this matches with the file name } } #[async_trait::async_trait] impl MigrationTrait for Migration { // Define how to apply this migration: Create the Bakery table. async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> { manager .create_table( Table::create() .table(Bakery::Table) .col( ColumnDef::new(Bakery::Id) .integer() .not_null() .auto_increment() .primary_key(), ) .col(ColumnDef::new(Bakery::Name).string().not_null()) .col(ColumnDef::new(Bakery::ProfitMargin).double().not_null()) .to_owned(), ) .await } // Define how to rollback this migration: Drop the Bakery table. async fn down(&self, manager: &SchemaManager) -> Result<(), DbErr> { manager .drop_table(Table::drop().table(Bakery::Table).to_owned()) .await } } #[derive(Iden)] pub enum Bakery { Table, Id, Name, ProfitMargin, } }
#![allow(unused)] fn main() { // m20220101_000002_create_chef_table.rs use sea_orm_migration::prelude::*; use super::m20220101_000001_create_bakery_table::Bakery; pub struct Migration; impl MigrationName for Migration { fn name(&self) -> &str { "m_20220101_000002_create_chef_table" // Make sure this matches with the file name } } #[async_trait::async_trait] impl MigrationTrait for Migration { // Define how to apply this migration: Create the Chef table. async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> { manager .create_table( Table::create() .table(Chef::Table) .col( ColumnDef::new(Chef::Id) .integer() .not_null() .auto_increment() .primary_key(), ) .col(ColumnDef::new(Chef::Name).string().not_null()) .col(ColumnDef::new(Chef::ContactDetails).json()) .col(ColumnDef::new(Chef::BakeryId).integer().not_null()) .foreign_key( ForeignKey::create() .name("fk-chef-bakery_id") .from(Chef::Table, Chef::BakeryId) .to(Bakery::Table, Bakery::Id), ) .to_owned(), ) .await } // Define how to rollback this migration: Drop the Chef table. async fn down(&self, manager: &SchemaManager) -> Result<(), DbErr> { manager .drop_table(Table::drop().table(Chef::Table).to_owned()) .await } } // For ease of access #[derive(Iden)] pub enum Chef { Table, Id, Name, ContactDetails, BakeryId, } }
#![allow(unused)] fn main() { // migration/src/lib.rs pub use sea_orm_migration::prelude::*; // Add each migration file as a module mod m20220101_000001_create_bakery_table; mod m20220101_000002_create_chef_table; pub struct Migrator; #[async_trait::async_trait] impl MigratorTrait for Migrator { fn migrations() -> Vec<Box<dyn MigrationTrait>> { vec![ // Define the order of migrations. Box::new(m20220101_000001_create_bakery_table::Migration), Box::new(m20220101_000002_create_chef_table::Migration), ] } } }
Important: Make sure the following features are enabled in the migration crate. The database driver feature must match the database being used.
# migration/Cargo.toml
...
[dependencies.sea-orm-migration]
version = "^0.12.0"
features = [
+ "sqlx-mysql",
+ "runtime-async-std-native-tls",
]
Perform the migrations
Perform all the migrations through sea-orm-cli:
Make sure you are running this command at the project root.
# Change the value of DATABASE_URL according to your database implementation.
# Make sure the database name is also supplied for MySQL or PostgreSQL.
$ DATABASE_URL="mysql://root:root@localhost:3306/bakeries_db" sea-orm-cli migrate refresh
Migration (API)
If you prefer to set up and run the migrations programmatically, we provide the Migrator API for that.
This section covers how to perform migrations without the need to install and use the CLI tool.
Preparation
Add the cargo dependency sea-orm-migration:
// Cargo.toml
...
[dependencies]
futures = "0.3.28"
sea-orm = { version = "^0.12.0", features = [ "sqlx-mysql", "runtime-async-std-native-tls", "macros" ] }
+ sea-orm-migration = "^0.12.0"
...
Create a module named migrator:
#![allow(unused)] fn main() { // src/main.rs + mod migrator; use futures::executor::block_on; use sea_orm::{ConnectionTrait, Database, DbBackend, DbErr, Statement}; ... }
#![allow(unused)] fn main() { // src/migrator/mod.rs (create new file) use sea_orm_migration::prelude::*; pub struct Migrator; #[async_trait::async_trait] impl MigratorTrait for Migrator { fn migrations() -> Vec<Box<dyn MigrationTrait>> { vec![] } } }
Define the migrations
Define a Migration in a file and include it in migrator/mod.rs:
The filename must follow the format m<date>_<6-digit-index>_<description>.rs.
For more information about defining migrations, read the documentation of SchemaManager.
#![allow(unused)] fn main() { // src/migrator/m20220602_000001_create_bakery_table.rs (create new file) use sea_orm_migration::prelude::*; pub struct Migration; impl MigrationName for Migration { fn name(&self) -> &str { "m_20220602_000001_create_bakery_table" } } #[async_trait::async_trait] impl MigrationTrait for Migration { // Define how to apply this migration: Create the Bakery table. async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> { manager .create_table( Table::create() .table(Bakery::Table) .col( ColumnDef::new(Bakery::Id) .integer() .not_null() .auto_increment() .primary_key(), ) .col(ColumnDef::new(Bakery::Name).string().not_null()) .col(ColumnDef::new(Bakery::ProfitMargin).double().not_null()) .to_owned(), ) .await } // Define how to rollback this migration: Drop the Bakery table. async fn down(&self, manager: &SchemaManager) -> Result<(), DbErr> { manager .drop_table(Table::drop().table(Bakery::Table).to_owned()) .await } } #[derive(Iden)] pub enum Bakery { Table, Id, Name, ProfitMargin, } }
#![allow(unused)] fn main() { // src/migrator/m20220602_000002_create_chef_table.rs (create new file) use sea_orm_migration::prelude::*; use super::m20220602_000001_create_bakery_table::Bakery; pub struct Migration; impl MigrationName for Migration { fn name(&self) -> &str { "m_20220602_000002_create_chef_table" } } #[async_trait::async_trait] impl MigrationTrait for Migration { // Define how to apply this migration: Create the Chef table. async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> { manager .create_table( Table::create() .table(Chef::Table) .col( ColumnDef::new(Chef::Id) .integer() .not_null() .auto_increment() .primary_key(), ) .col(ColumnDef::new(Chef::Name).string().not_null()) .col(ColumnDef::new(Chef::ContactDetails).json()) .col(ColumnDef::new(Chef::BakeryId).integer().not_null()) .foreign_key( ForeignKey::create() .name("fk-chef-bakery_id") .from(Chef::Table, Chef::BakeryId) .to(Bakery::Table, Bakery::Id), ) .to_owned(), ) .await } // Define how to rollback this migration: Drop the Chef table. async fn down(&self, manager: &SchemaManager) -> Result<(), DbErr> { manager .drop_table(Table::drop().table(Chef::Table).to_owned()) .await } } #[derive(Iden)] pub enum Chef { Table, Id, Name, ContactDetails, BakeryId, } }
#![allow(unused)] fn main() { // src/migrator/mod.rs use sea_orm_migration::prelude::*; + mod m20220602_000001_create_bakery_table; + mod m20220602_000002_create_chef_table; pub struct Migrator; #[async_trait::async_trait] impl MigratorTrait for Migrator { fn migrations() -> Vec<Box<dyn MigrationTrait>> { vec![ + Box::new(m20220602_000001_create_bakery_table::Migration), + Box::new(m20220602_000002_create_chef_table::Migration), ] } } }
Perform the migrations
Use the MigratorTrait API to perform the migrations. Verify the correctness of the database schema with SchemaManager.
#![allow(unused)] fn main() { // src/main.rs ... + use sea_orm_migration::prelude::*; ... async fn run() -> Result<(), DbErr> { ... + let schema_manager = SchemaManager::new(db); // To investigate the schema + Migrator::refresh(db).await?; + assert!(schema_manager.has_table("bakery").await?); + assert!(schema_manager.has_table("chef").await?); Ok(()) } ... }
Generate Entity from Database
Now that we have a database with a defined schema, we can generate the entities with sea-orm-cli.
sea-orm-cli is able to discover the schema given the database URL and generated the appropriate entity files.
# In case you have not installed `sea-orm-cli`
$ cargo install sea-orm-cli
# Generate entity files of database `bakeries_db` to `src/entities`
$ sea-orm-cli generate entity \
-u mysql://root:root@localhost:3306/bakeries_db \
-o src/entities
The generated entity files:
bakery-backend
├── Cargo.toml
├── migration
│ └── ...
└── src
├── entities
│ ├── chef.rs
│ ├── bakery.rs
│ ├── mod.rs
│ └── prelude.rs
└── main.rs
Put the focus on chef.rs and bakery.rs, they are the entities representing the tables Chef and Bakery, respectively.
Basic CRUD Operations
In this section, we showcase how to perform basic operations with the schema we've defined.
use the Entities
The entities are the Rust representation of the tables in the database. SeaORM enables us to make use of those entities to perform operations on the database programmatically.
#![allow(unused)] fn main() { // src/main.rs + mod entities; ... + use entities::{prelude::*, *}; ... }
Insert and Update
Insert and update operations can be performed using ActiveModel of the entities.
Let's insert a new bakery called Happy Bakery into our Bakery table.
#![allow(unused)] fn main() { // src/main.rs ... - use sea_orm::{ConnectionTrait, Database, DbBackend, DbErr, Statement}; + use sea_orm::*; ... async fn run() -> Result<(), DbErr> { ... let happy_bakery = bakery::ActiveModel { name: ActiveValue::Set("Happy Bakery".to_owned()), profit_margin: ActiveValue::Set(0.0), ..Default::default() }; let res = Bakery::insert(happy_bakery).exec(db).await?; } }
Suppose, later on, the owner of Happy Bakery adopts a brand new perspective of life, and renames it to Sad Bakery.
We can perform the update as follows:
#![allow(unused)] fn main() { let sad_bakery = bakery::ActiveModel { id: ActiveValue::Set(res.last_insert_id), name: ActiveValue::Set("Sad Bakery".to_owned()), profit_margin: ActiveValue::NotSet, }; sad_bakery.update(db).await?; }
Let's welcome John, the first employee of Sad Bakery!
#![allow(unused)] fn main() { let john = chef::ActiveModel { name: ActiveValue::Set("John".to_owned()), bakery_id: ActiveValue::Set(res.last_insert_id), // a foreign key ..Default::default() }; Chef::insert(john).exec(db).await?; }
Find (single entity)
We can find all or some of the bakeries in the database as follows:
#![allow(unused)] fn main() { // Finding all is built-in let bakeries: Vec<bakery::Model> = Bakery::find().all(db).await?; assert_eq!(bakeries.len(), 1); // Finding by id is built-in let sad_bakery: Option<bakery::Model> = Bakery::find_by_id(1).one(db).await?; assert_eq!(sad_bakery.unwrap().name, "Sad Bakery"); // Finding by arbitrary column with `filter()` let sad_bakery: Option<bakery::Model> = Bakery::find() .filter(bakery::Column::Name.eq("Sad Bakery")) .one(db) .await?; assert_eq!(sad_bakery.unwrap().id, 1); }
For relational select on multiple entities, visit the next section.
Delete
Sadly, Sad Bakery is unable to survive in the rapidly changing economy; it has been forced to liquidate!
We have no choice but to remove its entry in our database:
#![allow(unused)] fn main() { let john = chef::ActiveModel { id: ActiveValue::Set(1), // The primary key must be set ..Default::default() }; john.delete(db).await?; let sad_bakery = bakery::ActiveModel { id: ActiveValue::Set(1), // The primary key must be set ..Default::default() }; sad_bakery.delete(db).await?; let bakeries: Vec<bakery::Model> = Bakery::find().all(db).await?; assert!(bakeries.is_empty()); }
Relational Select
In the previous section, we explored how to perform select on a single entity.
However, relational databases are known for connecting entities with relations, such that we can perform queries across different entities.
For example, given a bakery, we can find all the chefs working there.
Suppose the following code were run before, inserting the bakery and the chefs it employed into the database.
#![allow(unused)] fn main() { let la_boulangerie = bakery::ActiveModel { name: ActiveValue::Set("La Boulangerie".to_owned()), profit_margin: ActiveValue::Set(0.0), ..Default::default() }; let bakery_res = Bakery::insert(la_boulangerie).exec(db).await?; for chef_name in ["Jolie", "Charles", "Madeleine", "Frederic"] { let chef = chef::ActiveModel { name: ActiveValue::Set(chef_name.to_owned()), bakery_id: ActiveValue::Set(bakery_res.last_insert_id), ..Default::default() }; Chef::insert(chef).exec(db).await?; } }
There are 4 chefs working at the bakery La Boulangerie, and we can find them later on as follows:
#![allow(unused)] fn main() { // First find *La Boulangerie* as a Model let la_boulangerie: bakery::Model = Bakery::find_by_id(bakery_res.last_insert_id) .one(db) .await? .unwrap(); let chefs: Vec<chef::Model> = la_boulangerie.find_related(Chef).all(db).await?; let mut chef_names: Vec<String> = chefs.into_iter().map(|b| b.name).collect(); chef_names.sort_unstable(); assert_eq!(chef_names, ["Charles", "Frederic", "Jolie", "Madeleine"]); }
As new bakeries open in the town, it would be inefficient to do find_related on each of the bakeries.
#![allow(unused)] fn main() { // Inserting two bakeries and their chefs let la_boulangerie = bakery::ActiveModel { name: ActiveValue::Set("La Boulangerie".to_owned()), profit_margin: ActiveValue::Set(0.0), ..Default::default() }; let bakery_res = Bakery::insert(la_boulangerie).exec(db).await?; for chef_name in ["Jolie", "Charles", "Madeleine", "Frederic"] { let chef = chef::ActiveModel { name: ActiveValue::Set(chef_name.to_owned()), bakery_id: ActiveValue::Set(bakery_res.last_insert_id), ..Default::default() }; Chef::insert(chef).exec(db).await?; } let la_id = bakery_res.last_insert_id; let arte_by_padaria = bakery::ActiveModel { name: ActiveValue::Set("Arte by Padaria".to_owned()), profit_margin: ActiveValue::Set(0.2), ..Default::default() }; let bakery_res = Bakery::insert(arte_by_padaria).exec(db).await?; for chef_name in ["Brian", "Charles", "Kate", "Samantha"] { let chef = chef::ActiveModel { name: ActiveValue::Set(chef_name.to_owned()), bakery_id: ActiveValue::Set(bakery_res.last_insert_id), ..Default::default() }; Chef::insert(chef).exec(db).await?; } let arte_id = bakery_res.last_insert_id; // would then need two sets of find_related to find }
We can utilize a loader to do the heavy lifting for us.
#![allow(unused)] fn main() { // First find bakeries as Models let bakeries: Vec<bakery::Model> = Bakery::find() .filter( Condition::any() .add(bakery::Column::Id.eq(la_id)) .add(bakery::Column::Id.eq(arte_id)) ) .all(db) .await?; // Then use loader to load the chefs in one query. let chefs: Vec<Vec<chef::Model>> = bakeries.load_many(Chef, db).await?; let mut la_chef_names: Vec<String> = chefs[0].to_owned().into_iter().map(|b| b.name).collect(); la_chef_names.sort_unstable(); let mut arte_chef_names: Vec<String> = chefs[1].to_owned().into_iter().map(|b| b.name).collect(); arte_chef_names.sort_unstable(); assert_eq!(la_chef_names, ["Charles", "Frederic", "Jolie", "Madeleine"]); assert_eq!(arte_chef_names, ["Brian", "Charles", "Kate", "Samantha"]); }
Using a loader can greatly reduce the traffic of the database.
For more advanced usage, visit the documentation.
Testing with Mock Interface
In some cases, we want to verify the application logic without using a real database. As such, SeaORM provides a MockDatabase interface to be used in development.
For example, we don't want to set up and use a real database for unit testing because the database layer should be independent of the application logic layer. Using a mock interface provides stable and correct behavior in the database layer, hence any errors that emerge can only be due to bugs in the application logic layer.
Also, a real database may not be preferred when we want to maximize the portability of the development environment. Using a mock interface effective takes away the need for setting up and maintaining a real database, therefore application logic developers can do their work virtually anywhere.
Add the mock Cargo feature
// Cargo.toml
...
- sea-orm = { version = "^0.12.0", features = [ ... ] }
+ sea-orm = { version = "^0.12.0", features = [ ... , "mock" ] }
...
Define the expected query results
First, we define what we want our mock database to return.
Note that the function append_query_results() takes a vector of vectors, where each vector nested inside represent the result of a single query.
#![allow(unused)] fn main() { let db: &DatabaseConnection = &MockDatabase::new(DatabaseBackend::MySql) .append_query_results([ // First query result vec![bakery::Model { id: 1, name: "Happy Bakery".to_owned(), profit_margin: 0.0, }], // Second query result vec![ bakery::Model { id: 1, name: "Happy Bakery".to_owned(), profit_margin: 0.0, }, bakery::Model { id: 2, name: "Sad Bakery".to_owned(), profit_margin: 100.0, }, bakery::Model { id: 3, name: "La Boulangerie".to_owned(), profit_margin: 17.89, }, ], ]) .append_query_results([ // Third query result vec![ chef::Model { id: 1, name: "Jolie".to_owned(), contact_details: None, bakery_id: 3, }, chef::Model { id: 2, name: "Charles".to_owned(), contact_details: None, bakery_id: 3, }, chef::Model { id: 3, name: "Madeleine".to_owned(), contact_details: None, bakery_id: 3, }, chef::Model { id: 4, name: "Frederic".to_owned(), contact_details: None, bakery_id: 3, }, ] ]) .into_connection(); }
Note: if a query result contains multiple models (like the second and third ones above) and Entity::find().one(db) is called, only the first one will be returned. The rest of the models in the query will be discarded.
Use the returned query results
Then the query results can be mocked and passed to other parts of the application logic.
#![allow(unused)] fn main() { let happy_bakery: Option<bakery::Model> = Bakery::find().one(db).await?; assert_eq!( happy_bakery.unwrap(), bakery::Model { id: 1, name: "Happy Bakery".to_owned(), profit_margin: 0.0, } ); let all_bakeries: Vec<bakery::Model> = Bakery::find().all(db).await?; assert_eq!( all_bakeries, vec![ bakery::Model { id: 1, name: "Happy Bakery".to_owned(), profit_margin: 0.0, }, bakery::Model { id: 2, name: "Sad Bakery".to_owned(), profit_margin: 100.0, }, bakery::Model { id: 3, name: "La Boulangerie".to_owned(), profit_margin: 17.89, }, ] ); let la_boulangerie_chefs: Vec<chef::Model> = Chef::find().all(db).await?; assert_eq!( la_boulangerie_chefs, vec![ chef::Model { id: 1, name: "Jolie".to_owned(), contact_details: None, bakery_id: 3, }, chef::Model { id: 2, name: "Charles".to_owned(), contact_details: None, bakery_id: 3, }, chef::Model { id: 3, name: "Madeleine".to_owned(), contact_details: None, bakery_id: 3, }, chef::Model { id: 4, name: "Frederic".to_owned(), contact_details: None, bakery_id: 3, }, ] ); }
Mock execution results
To mock the results of CRUD operations, we can use append_exec_results().
As it is highly similar to the above, it won't be covered in detail in this tutorial. For more information, refer to the documentation.
Optional: Building SQL Queries with SeaQuery
If you prefer the flexibility of SQL, you can use SeaQuery to build SQL-like statements for any queries or operations.
SeaQuery is built-in for SeaORM, so no extra setup is required.
Insert statements
Raw SQL:
INSERT INTO `bakery` (`name`, `profit_margin`) VALUES ('SQL Bakery', -100)
SeaQuery:
#![allow(unused)] fn main() { use sea_query::{Alias, Query}; let columns: Vec<Alias> = ["name", "profit_margin"] .into_iter() .map(Alias::new) .collect(); let mut stmt = Query::insert(); stmt.into_table(bakery::Entity).columns(columns); // Invoke `values_panic()` for each row stmt.values_panic(["SQL Bakery".into(), (-100.0).into()]); let builder = db.get_database_backend(); db.execute(builder.build(&stmt)).await?; }
Select statements
Raw SQL:
SELECT `chef`.`name` FROM `chef` JOIN `bakery` ON `chef`.`bakery_id` = `bakery`.`id` ORDER BY `chef`.`name` ASC
SeaQuery:
If you are only interested in some of the columns, define a struct to hold the query result. It has to derive from the trait FromQueryResult.
If all columns are of interest, then the generated Model structs (e.g. chef::Model) can be used.
The fields of the struct must match the column names of the query result.
#![allow(unused)] fn main() { use sea_query::{Alias, Expr, JoinType, Order, Query}; #[derive(FromQueryResult)] struct ChefNameResult { name: String, } ... let column = (chef::Entity, Alias::new("name")); let mut stmt = Query::select(); stmt.column(column.clone()) // Use `expr_as` instead of `column` if renaming is necessary .from(chef::Entity) .join( JoinType::Join, bakery::Entity, Expr::col((chef::Entity, Alias::new("bakery_id"))) .equals((bakery::Entity, Alias::new("id"))), ) .order_by(column, Order::Asc); let builder = db.get_database_backend(); let chef = ChefNameResult::find_by_statement(builder.build(&stmt)) .all(db) .await?; let chef_names = chef.into_iter().map(|b| b.name).collect::<Vec<_>>(); assert_eq!( chef_names, vec!["Charles", "Frederic", "Jolie", "Madeleine"] ); }
Testing and Debugging
It's often useful to check the raw SQL of the SeaQuery-generated statements.
Use stmt.to_string(query_builder) to do that.
#![allow(unused)] fn main() { // Check the raw SQL of `stmt` in MySQL syntax println!({}, stmt.to_string(MysqlQueryBuilder)); }
Chapter 2 - Integration with Rocket
Full source code available on GitHub.
In Chapter 1, we've explored how to interact with a database in Rust.
In real applications, however, we'd probably want to expose those operations in a Web API for generic usage.
To achieve that, we leverage web frameworks like Rocket.
You'll soon discover how simple and painless it is to use SeaORM in a Rocket application!
Create a Rocket project
Create a new binary crate:
$ cargo new rocket-example --bin
$ cd rocket-example
Add rocket as a dependency:
# Cargo.toml
...
[dependencies]
+ rocket = { version = "^0.5.0-rc.2", features = ["json"] }
...
Pay attention to the version that you're using. rocket and/or its dependencies may not compile on the stable build of the Rust compiler if an early version of rocket is used.
The following should compile and run:
#![allow(unused)] fn main() { // src/main.rs use rocket::*; #[get("/")] async fn index() -> &'static str { "Hello, bakeries!" } #[launch] // The "main" function of the program fn rocket() -> _ { rocket::build().mount("/", routes![index]) } }
To verify it works:
$ cargo run
GET localhost:8000/
"Hello, bakeries!"
Connect to Database
First, we define a function to help us create a database and/or connect to it.
It is basically the same as in Section 1.1.
#![allow(unused)] fn main() { // src/setup.rs use sea_orm::*; // Replace with your database URL and database name const DATABASE_URL: &str = "mysql://root:root@localhost:3306"; const DB_NAME: &str = "bakeries_db"; pub(super) async fn set_up_db() -> Result<DatabaseConnection, DbErr> { let db = Database::connect(DATABASE_URL).await?; let db = match db.get_database_backend() { DbBackend::MySql => { db.execute(Statement::from_string( db.get_database_backend(), format!("CREATE DATABASE IF NOT EXISTS `{}`;", DB_NAME), )) .await?; let url = format!("{}/{}", DATABASE_URL, DB_NAME); Database::connect(&url).await? } DbBackend::Postgres => { db.execute(Statement::from_string( db.get_database_backend(), format!("DROP DATABASE IF EXISTS \"{}\";", DB_NAME), )) .await?; db.execute(Statement::from_string( db.get_database_backend(), format!("CREATE DATABASE \"{}\";", DB_NAME), )) .await?; let url = format!("{}/{}", DATABASE_URL, DB_NAME); Database::connect(&url).await? } DbBackend::Sqlite => db, }; Ok(db) } }
We instruct Rocket to manage the database connection as a state.
#![allow(unused)] fn main() { // src/main.rs #[launch] fn rocket() -> _ { + let db = match set_up_db().await { + Ok(db) => db, + Err(err) => panic!("{}", err), + }; rocket::build() + .manage(db) .mount("/", routes![index, bakeries]) } }
The database connection can then be accessed and used as in previous sections.
#![allow(unused)] fn main() { // src/main.rs use rocket::serde::json::Json; ... #[get("/bakeries")] async fn bakeries(db: &State<DatabaseConnection>) -> Json<Vec<String>> { let db = db as &DatabaseConnection; let bakery_names = Bakery::find() .all(db) .await .unwrap() .into_iter() .map(|b| b.name) .collect::<Vec<String>>(); Json(bakery_names) } ... #[launch] fn rocket() -> _ { rocket::build() .mount( "/", // Don't forget to mount the new endpoint handlers routes![ index, + bakeries ] ) } }
To verify it works:
$ cargo run
GET localhost:8000/bakeries
["Bakery Names", "In The", "Database", "If Any"]
Error Handling
First, define a custom responder:
#![allow(unused)] fn main() { // src/main.rs #[derive(Responder)] #[response(status = 500, content_type = "json")] struct ErrorResponder { message: String, } // The following impl's are for easy conversion of error types. impl From<DbErr> for ErrorResponder { fn from(err: DbErr) -> ErrorResponder { ErrorResponder { message: err.to_string(), } } } impl From<String> for ErrorResponder { fn from(string: String) -> ErrorResponder { ErrorResponder { message: string } } } impl From<&str> for ErrorResponder { fn from(str: &str) -> ErrorResponder { str.to_owned().into() } } }
To catch and handle the errors:
#![allow(unused)] fn main() { // src/main.rs #[get("/bakeries")] async fn bakeries(db: &State<DatabaseConnection>) - -> Json<Vec<String>> + -> Result<Json<Vec<String>>, ErrorResponder> { let db = db as &DatabaseConnection; let bakery_names = Bakery::find() .all(db) .await - .unwrap() + .map_err(Into::into)? .into_iter() .map(|b| b.name) .collect::<Vec<String>>(); - Json(bakery_names) + Ok(Json(bakery_names)) } }
Web API Integration
We can wrap more of the backend's functionalities into our Rocket application.
Check Rocket's official documentation for how to use their interfaces.
Below are some examples: (Don't forget to mount all new handlers in rocket()!)
Fetch one Bakery by id
#![allow(unused)] fn main() { #[get("/bakeries/<id>")] async fn bakery_by_id(db: &State<DatabaseConnection>, id: i32) -> Result<String, ErrorResponder> { let db = db as &DatabaseConnection; let bakery = Bakery::find_by_id(id).one(db).await.map_err(Into::into)?; Ok(if let Some(bakery) = bakery { bakery.name } else { return Err(format!("No bakery with id {id} is found.").into()); }) } }
Add a new Bakery
Query parameters are used for input here for simplicity. Alternatively, use Body Data.
#![allow(unused)] fn main() { use entities::*; #[post("/bakeries?<name>&<profit_margin>")] async fn new_bakery( db: &State<DatabaseConnection>, name: &str, profit_margin: Option<f64>, ) -> Result<(), ErrorResponder> { let db = db as &DatabaseConnection; let new_bakery = bakery::ActiveModel { name: ActiveValue::Set(name.to_owned()), profit_margin: ActiveValue::Set(profit_margin.unwrap_or_default()), ..Default::default() }; Bakery::insert(new_bakery) .exec(db) .await .map_err(Into::into)?; Ok(()) } }
Optional: Simple Frontend Using Templates
To make your application a little more accessible, Rocket provides the Templates interface for frontend support.
Follow their guide for a more comprehensive documentation.
Some examples can be found in the SeaORM official Rocket example and rocket-example in the repo of this tutorial.
Chapter 3 - Integration with GraphQL
Full source code available on GitHub.
We've created a web application with Rocket in Chapter 2, but you may notice that the RESTful API of the application lacks flexibility.
For example, a GET request to the endpoint /bakeries, if successful, always gives us an array of names of the bakeries in the database. This is a toy implementation to demonstrate how things could work, but in reality we also need to provide ways for getting other attributes (e.g. profit_margin).
If we simply return everything in a response every time, the user ends up receiving extra data they didn't need. If we want to keep things small, we'll have to design and model different use cases and create many endpoints to cater for them.
To combat this, GraphQL, an alternative solution to RESTful API's, provides the flexibility we (may) need.
With GraphQL, the user describes the desired data in the request body. Then the server prepares exactly that and sends it back in the response. As a result, only one endpoint is needed and no extra data is transmitted.
As the experience is greatly enhanced on the client side, the burden of implementing ways to retrieve data flexibly is heavier on the server side. This problem is severe in the world of JavaScript, as quite a lot of boilerplate code is required to implement a GraphQL server there. However, thanks to Rust's powerful type system and macro support, many of GraphQL's features can actually be implemented rather painlessly.
In this chapter, we'll build a Rocket application with GraphQL support powered by async_graphql. Of course, SeaORM will serve as the bridge between the GraphQL resolvers and the database.
Project Setup
Create a Rocket application
The initial setup of this chapter is vastly similar to that of the previous chapter.
Refer to Section 2.1 and Section 2.2 to create a Rocket application and configure the database connection.
Set up async_graphql support
Add the crates as dependencies:
// Cargo.toml
...
[dependencies]
+ async-graphql = "6.0.4"
+ async-graphql-rocket = "6.0.4"
...
Make sure the entities are generated (Section 1.4), and extend them to support basic GraphQL queries by attributes:
#![allow(unused)] fn main() { // src/entities/chef.rs + use async_graphql::SimpleObject; use sea_orm::entity::prelude::*; - #[derive(Clone, Debug, PartialEq, DeriveEntityModel)] + #[derive(Clone, Debug, PartialEq, DeriveEntityModel, SimpleObject)] #[sea_orm(table_name = "chef")] pub struct Model { ... }
#![allow(unused)] fn main() { // src/entities/bakery.rs + use async_graphql::SimpleObject; use sea_orm::entity::prelude::*; - #[derive(Clone, Debug, PartialEq, DeriveEntityModel)] + #[derive(Clone, Debug, PartialEq, DeriveEntityModel, SimpleObject)] #[sea_orm(table_name = "bakery")] pub struct Model { ... }
Create a struct to serve as the root of queries. The root level query requests will be defined here:
#![allow(unused)] fn main() { // src/schema.rs use async_graphql::Object; pub(crate) struct QueryRoot; #[Object] impl QueryRoot { async fn hello(&self) -> String { "Hello GraphQL".to_owned() } } }
Build the Schema and attach it to Rocket as a state, and create an endpoint to serve GraphQL requests:
#![allow(unused)] fn main() { // src/main.rs mod entities; mod migrator; + mod schema; mod setup; + use async_graphql::{EmptyMutation, EmptySubscription, Schema}; + use async_graphql_rocket::*; use rocket::*; + use schema::*; use sea_orm::*; use setup::set_up_db; + type SchemaType = Schema<QueryRoot, EmptyMutation, EmptySubscription>; ... + #[rocket::post("/graphql", data = "<request>", format = "application/json")] + async fn graphql_request(schema: &State<SchemaType>, request: GraphQLRequest) -> GraphQLResponse { + request.execute(schema).await + } ... #[launch] async fn rocket() -> _ { let db = match set_up_db().await { Ok(db) => db, Err(err) => panic!("{}", err), }; // Build the Schema + let schema = Schema::build(QueryRoot, EmptyMutation, EmptySubscription) + .data(db) // Add the database connection to the GraphQL global context + .finish(); rocket::build() - .manage(db) // db is now managed by schema + .manage(schema) // schema is managed by rocket - .mount("/", routes![index]) + .mount("/", routes![index, graphql_request]) .register("/", catchers![not_found]) } ... }
To verify it works:
$ cargo run
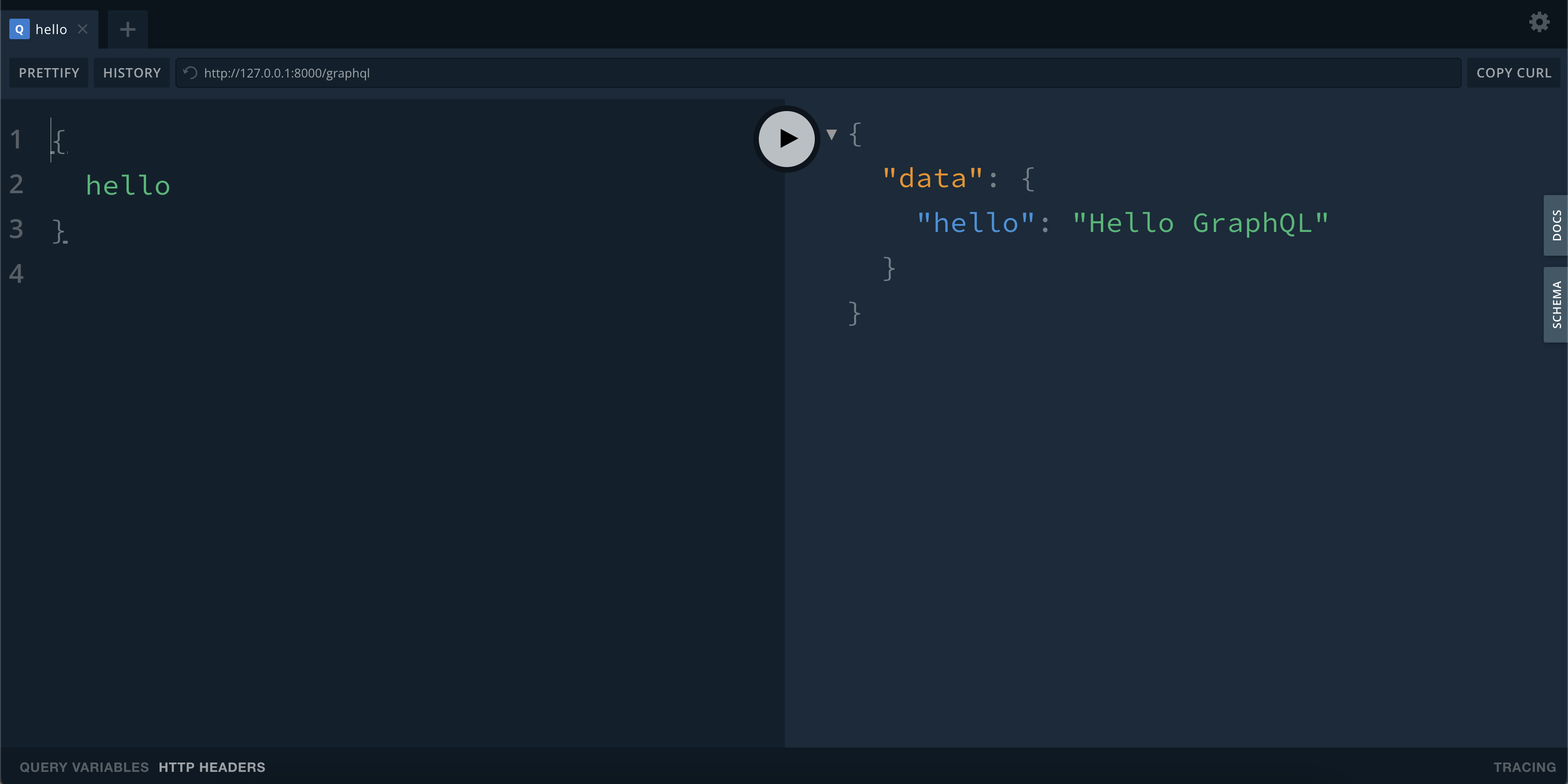
For debugging, GraphQL requests can be sent via the GraphQL Playground.
GraphQL Request:
{
hello
}
Response:
{
"data": {
"hello": "Hello GraphQL"
}
}
Query with GraphQL
To support queries, we extend the QueryRoot struct:
Basic Queries
#![allow(unused)] fn main() { // src/schema.rs - use async_graphql::Object; + use async_graphql::{Context, Object}; + use sea_orm::*; + use crate::entities::{prelude::*, *}; pub(crate) struct QueryRoot; #[Object] impl QueryRoot { ... // For finding all bakeries + async fn bakeries(&self, ctx: &Context<'_>) -> Result<Vec<bakery::Model>, DbErr> { + let db = ctx.data::<DatabaseConnection>().unwrap(); + Bakery::find().all(db).await + } // For finding one bakery by id + async fn bakery(&self, ctx: &Context<'_>, id: i32) -> Result<Option<bakery::Model>, DbErr> { + let db = ctx.data::<DatabaseConnection>().unwrap(); + + Bakery::find_by_id(id).one(db).await + } } }
Example queries:
GraphQL Request:
{
bakeries {
name
}
}
Response:
{
"data": {
"bakeries": [
{
"name": "ABC Bakery"
},
{
"name": "La Boulangerie"
},
{
"name": "Sad Bakery"
}
]
}
}
GraphQL Request:
{
bakery(id: 1) {
name
}
}
Response:
{
"data": {
"bakery": {
"name": "ABC Bakery"
}
}
}
If name is replaced by other fields of bakery::Model, the requests will automatically be supported. This is because bakery::Model derives from async_graphql::SimpleObject in the previous section.
Relational Query
One of the most appealing features of GraphQL is its convenient support for relational queries.
Recall that a Bakery may hire many chefs. We can give bakery::Model ComplexObject support to allow for this relational query.
#![allow(unused)] fn main() { // src/entities/bakery.rs #[derive(Clone, Debug, PartialEq, DeriveEntityModel, SimpleObject)] + #[graphql(complex, name = "Bakery")] #[sea_orm(table_name = "bakery")] pub struct Model { ... }
#![allow(unused)] fn main() { // src/schema.rs - use async_graphql::{Context, Object}; + use async_graphql::{ComplexObject, Context, Object}; ... + #[ComplexObject] + impl bakery::Model { + async fn chefs(&self, ctx: &Context<'_>) -> Result<Vec<chef::Model>, DbErr> { + let db = ctx.data::<DatabaseConnection>().unwrap(); + + self.find_related(Chef).all(db).await + } + } }
Example query:
GraphQL Request:
{
bakery(id: 1) {
name,
chefs {
name
}
}
}
Response:
{
"data": {
"bakery": {
"name": "ABC Bakery",
"chefs": [
{
"name": "Sanford"
},
{
"name": "Billy"
}
]
}
}
}
Mutation
Preparation
To support mutations with GraphQL, we need to create a struct to serve as the root, as for queries.
#![allow(unused)] fn main() { // src/schema.rs ... pub(crate) struct QueryRoot; + pub(crate) struct MutationRoot; ... }
#![allow(unused)] fn main() { // src/main.rs ... - use async_graphql::{EmptyMutation, EmptySubscription, Schema}; + use async_graphql::{EmptySubscription, Schema}; ... - type SchemaType = Schema<QueryRoot, EmptyMutation, EmptySubscription>; + type SchemaType = Schema<QueryRoot, MutationRoot, EmptySubscription>; ... #[launch] async fn rocket() -> _ { let db = match set_up_db().await { Ok(db) => db, Err(err) => panic!("{}", err), }; - let schema = Schema::build(QueryRoot, EmptyMutation, EmptySubscription) + let schema = Schema::build(QueryRoot, MutationRoot, EmptySubscription) .data(db) // Add the database connection to the GraphQL global context .finish(); ... }
Define resolvers
Define the mutation resolvers just like the ones for queries:
#![allow(unused)] fn main() { // src/schema.rs ... #[Object] impl MutationRoot { // For inserting a bakery async fn add_bakery(&self, ctx: &Context<'_>, name: String) -> Result<bakery::Model, DbErr> { let db = ctx.data::<DatabaseConnection>().unwrap(); let res = Bakery::insert(bakery::ActiveModel { name: ActiveValue::Set(name), profit_margin: ActiveValue::Set(0.0), ..Default::default() }) .exec(db) .await?; Bakery::find_by_id(res.last_insert_id) .one(db) .await .map(|b| b.unwrap()) } // For inserting a chef async fn add_chef( &self, ctx: &Context<'_>, name: String, bakery_id: i32, ) -> Result<chef::Model, DbErr> { let db = ctx.data::<DatabaseConnection>().unwrap(); let res = Chef::insert(chef::ActiveModel { name: ActiveValue::Set(name), bakery_id: ActiveValue::Set(bakery_id), ..Default::default() }) .exec(db) .await?; Chef::find_by_id(res.last_insert_id) .one(db) .await .map(|b| b.unwrap()) } } }
Examples:
GraphQL Request:
mutation {
addChefy(name: "Excellent Bakery") {
id,
name,
profitMargin
}
}
Response:
{
"data": {
"addChefy": {
"id": 4,
"name": "Excellent Bakery",
"profitMargin": 0
}
}
}
GraphQL Request:
mutation {
addChef(name: "Chris", bakeryId: 1) {
id,
name,
bakery {
chefs {
name
}
}
}
}
Response:
{
"data": {
"addChef": {
"id": 3,
"name": "Chris",
"bakery": {
"chefs": [
{
"name": "Sanford"
},
{
"name": "Billy"
},
{
"name": "Chris"
}
]
}
}
}
}
Optional: GraphQL Playground
Overview
When you are developing the GraphQL API, you probably want to send requests to verify the correctness of your implementation.
A locally hosted GraphQL Playground is perfect for this.
Simply type your request body on the left and the response data will be shown on the right.
Setup
Add a GET handler that returns a rocket::response::content::RawHTML<String>, which is the Playground HTML generated by async-graphql:
#![allow(unused)] fn main() { // src/main.rs ... use async_graphql::{EmptySubscription, Schema}; use async_graphql::{ + http::{playground_source, GraphQLPlaygroundConfig}, EmptySubscription, Schema, }; use async_graphql_rocket::*; - use rocket::*; + use rocket::{response::content, *}; ... + #[rocket::get("/graphql")] + fn graphql_playground() -> content::RawHtml<String> { + content::RawHtml(playground_source(GraphQLPlaygroundConfig::new("/graphql"))) + } ... rocket::build() .manage(schema) - .mount("/", routes![index, graphql_request]) + .mount("/", routes![index, graphql_playground, graphql_request]) ... }
Major Merits
Autocomplete requests
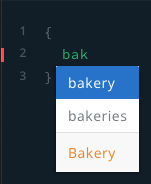
The Playground discovers all the types and their attributes and autocompletes your requests for you.
Preview Documentation
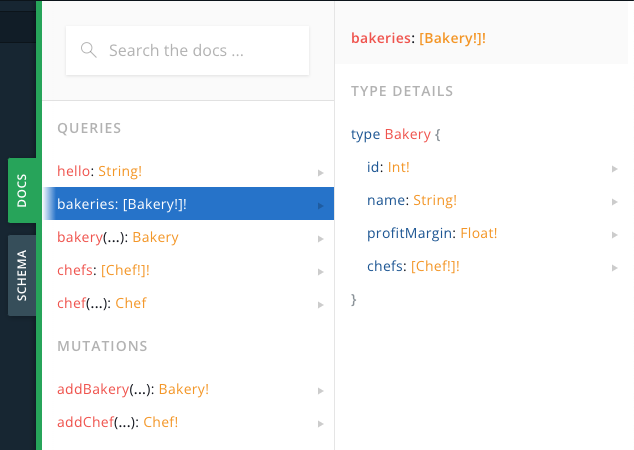
You can open up the DOCS panel on the side to see the comprehensive documentation for your GraphQL API.
Export Schema
On the SCHEMA panel, you can view the schema of your GraphQL API, and export it in JSON or SDL format.
Appendix
Thanks for reading the SeaORM tutorial from start to end! Glad you make it this far!!
We have a few more things for you, read on!
Seaography
If you are building a web API that perform selecting nested relation extensively. Consider serving a GraphQL server instead. seaography is a GraphQL framework for building GraphQL resolvers using SeaORM entities. With GraphQL resolver in place select above nested relation is straightforward and easy. Check "Getting Started with Seaography" to learn more.
Cookbook
The SeaORM Cookbook is a collection of frequently asked questions and the best practice of SeaORM.