Seaography 2.0: A Powerful and Extensible GraphQL Framework 🧭


GraphQL has become the preferred interface for product teams. Both frontend and backend developers benefit from its type-safety, contractual guarantees, and composability. Yet the real challenge lies on the backend: implementing relational resolvers that can traverse complex schemas is often difficult and time-consuming.
Yes, there are libraries that can spin up a GraphQL resolver quickly, but they often come with trade-offs: they're hard to customize, making it painful to add additional endpoints when your application grows beyond the basics.
The hardest challenge is customization. Real-world applications demand fine-grained permissions and context-dependent business logic. Seaography is designed to solve this exact problem, offering:
- Automatic GraphQL resolver generation with data loader integration to solve the N+1 problem
- Extensive customization options and the ability to add custom endpoints easily
- Authorization: Role-Based Access Control (RBAC) and fine-grained control with hooks / guards
🧭 What is Seaography
A video is worth a thousand words, so let's look at a quick demo.
In under a minute, we've done the following:
- Generate SeaORM entities from an existing sakila database (SQLite in demo)
- Generate a GraphQL web server around the entities (supports Axum, Actix, Poem)
- Launch it and run some queries with GraphQL playground
This is of course a speed run, but you can follow the same steps easily, and the generated framework is fully customizable.
What kinds of queries are supported?
Filter, Ordering and Pagination
{
film(
filters: {
title: { contains: "sea" } # ⬅ like '%sea%'
and: [{ releaseYear: { gt: "2000" } }, { length: { gt: 120 } }]
# ⬆ composable attribute filters
}
orderBy: { filmId: ASC }
pagination: { page: { page: 0, limit: 10 } }
# ⬆ cursor based pagination is also supported:
# pagination: { cursor: { limit: 10, cursor: "Int[3]:100" } }
) {
nodes {
filmId
title
description
}
paginationInfo {
pages
current
}
}
}
Nested Relational Query
The following query finds us all the documentaries starred by the actor "David" along with the stores having it in stock so that we can go rent it.
{
film(
# ⬇ filter by related entity
having: { # ⬅ where exists (..) AND (..)
actor: { firstName: { eq: "David" } }
category: { name: { eq: "Documentary" } }
}
) {
nodes {
filmId
title
# ⬇ skipped the film_actor junction
actor {
nodes {
firstName
lastName
}
}
# ⬇ nested relational query
inventory {
nodes {
store {
address {
address
city {
city
}
}
}
}
}
}
}
}
There are two join paths in this query:
film -> film_actor -> actor
-> inventory -> store -> address -> city
A data loader is used for resolving the relations, such that it does not suffers from the N+1 problem.
Mutations: create, update, delete
Full CRUD is supported, including CreateOne CreateBatch Update and Delete.
mutation {
# ⬇ operations will be executed inside a transaction
filmTextCreateBatch(
data: [
{ filmId: 1, title: "Foo bar", description: "Lorem ipsum dolor sit amet" }
{ filmId: 2, title: "Fizz buzz", description: "Consectetur adipiscing elit" }
]
) {
filmId
title
description
}
}
Custom Query
The above is not something entirely new, as some features already exist in Seaography 1.0. The real game-changer is how you can implement custom endpoints and mix-and-match them with SeaORM entities. Let's dive into it!
Custom Query with pagination
Seaography 2.0 introduced a set of macros to allow you to write custom query endpoints by reusing facilities in Seaography.
Let's say we have a Customer entity:
//! This is an entity from the sakila schema, generated by sea-orm-cli
use sea_orm::entity::prelude::*;
#[derive(Clone, Debug, PartialEq, DeriveEntityModel, Eq)]
#[sea_orm(table_name = "customer")]
pub struct Model {
#[sea_orm(primary_key, auto_increment = false)]
pub customer_id: i32,
pub store_id: i32,
pub first_name: String,
pub last_name: String,
..
}
We want to create a custom endpoint, like the one Seaography already provides, but with an additional requirement: only return customers of the current store from which the user makes request from.
use seaography::{apply_pagination, Connection, CustomFields, PaginationInput};
pub struct Operations;
#[CustomFields]
impl Operations {
async fn customer_of_current_store(
ctx: &Context<'_>,
pagination: PaginationInput,
// ⬆ this input struct is provided by Seaography
) -> async_graphql::Result<Connection<customer::Entity>> {
// this output struct ⬆ is provided by Seaography
let db = ctx.data::<DatabaseConnection>()?;
// ⬆ this is a normal SeaORM db connection
let session = ctx.data::<Session>()?;
// ⬆ this session is inject by the HTTP handler
let query = customer::Entity::find()
// ⬆ this is the same old SeaORM API
.filter(customer::Column::StoreId.eq(session.store_id));
// ⬆ here we implement our custom logic
// note that here, we haven't execute the query yet ..
// instead, we pass it to Seaography to handle the rest!
let connection = apply_pagination(&CONTEXT, db, query, pagination).await?;
// now the query executes ⬆
Ok(connection)
}
}
This would expose the following query endpoint:
customer_of_current_store(
pagination: PaginationInput
): CustomerConnection!
Query it like the following:
{
customer_of_current_store(pagination: { page: { page: 0, limit: 10 } }) {
nodes {
storeId
customerId
firstName
lastName
email
}
paginationInfo {
pages
current
}
}
}
It's almost effortless, right? In just a few lines of code, we've added a new API endpoint that does a lot under the hood. But the heavylifting is done by Seaography + SeaORM.
How does it work?
On a very high-level, how it all works:
- Seaography bridges SeaORM types with Async GraphQL, such that any SeaORM entity can be used as GraphQL output
- The schema meta of SeaORM entities are transformed into GraphQL schema on-the-fly on application startup
The lifecycle of a GraphQL request:
- Async GraphQL parses the HTTP request and construct a GraphQL request context
- Your http handler intercepts this request and adds in additional session context
- This GraphQL request is passed to Seaography
- Seaography parses the input types and then construct the Rust types
- Your async resolver is called, performing some business logic and returns result to Seaography
- Seaography transforms the output and return to Async GraphQL
- Async GraphQL does some final checks and serializes everything into a HTTP response
You may wonder, isn't the above kind of already possible by using Async GraphQL's derive macros, for example, by deriving SimpleObject on a SeaORM entity?
Actually this is how Seaography 0.1 worked in its initial release. However, the complex queries we shown you in the beginning is only achievable with a dynamic schema, but in Async GraphQL the static and dynamic schemas are completely different type systems - they can't inter-operate ... until now!
The difference is, the transformation between SeaORM Model <-> GraphQL Model happens dynamically, so there's not a ton of code generated beneath the surface.
Custom Mutation
Let's continue on making custom mutation endpoints. Say now we want to create a transactional endpoint for staff members in store to handle customer rentals.
First we can design the data structures for the input form:
use sea_orm::entity::prelude::{DateTimeUtc};
use seaography::{async_graphql, CustomFields, CustomInputType};
#[derive(Clone, CustomInputType)]
pub struct RentalRequest {
pub customer: String,
pub film: String,
pub coupon: Option<Coupon>,
pub timestamp: DateTimeUtc,
}
#[derive(Clone, CustomInputType)]
pub struct Coupon {
pub code: String,
pub points: Option<Decimal>,
}
Then we can define the mutation endpoint. The business logic is:
- Look up the specifc customer and film
- Find if there is inventory in store. If not, return error
- Create a new rental record and remove the item from inventory
#[CustomFields]
impl Operations {
async fn rental_request(
ctx: &Context<'_>,
rental_request: RentalRequest,
// ⬆ our custom input struct
) -> async_graphql::Result<rental::Model> {
// ⬆ a normal SeaORM Model
let db = ctx.data::<DatabaseConnection>()?;
let session = ctx.data::<Session>()?;
let txn = db.begin().await?;
// ⬆ create a transaction to make operation atomic
let customer = Customer::find_by_name(rental_request.customer, &txn).await?;
let film = Film::find_by_title(rental_request.film, &txn).await?;
// ⬆ helper methods to find the corresponding customer and film
// ⬇ find if there is inventory in current store
let inventory = Inventory::find()
.filter(inventory::Column::FilmId.eq(film.id))
.filter(inventory::Column::StoreId.eq(session.store_id))
.one(&txn)
.unwrap_or(Error::NoInventory)?;
// ⬆ return error if no inventory
let rental = rental::ActiveModel {
rental_date: Set(rental_request.timestamp),
inventory_id: Set(inventory.id),
customer_id: Set(customer.id),
staff_id: Set(session.staff_id), // ⬅ current staff
last_update: Set(Utc::now()),
..Default::default()
}.insert(&txn).await?;
inventory.delete(&txn).await?;
// ⬆ now remove it from inventory
txn.commit().await?;
// ⬇ return the newly created rental record
Ok(rental)
}
}
The Coupon object is used to demonstrate that nested objects are supported, and it will be reflected in the GraphQL schema. I will leave it as an exercise for you to fit in the logic for handling it.
Custom methods and unions
The GraphQL type system is very expressive (so is Rust), and so I want to demonstrate two more advanced features:
#[derive(Clone, CustomInputType, CustomOutputType)]
pub struct Rectangle {
pub origin: Point,
pub size: Size,
}
#[CustomFields]
impl Rectangle {
pub async fn area(&self) -> async_graphql::Result<f64> {
// ⬆ this is an instance method
Ok(self.size.width * self.size.height)
}
}
#[derive(Clone, CustomInputType, CustomOutputType)]
pub struct Circle {
pub center: Point,
pub radius: f64,
}
#[CustomFields]
impl Circle {
pub async fn area(&self) -> async_graphql::Result<f64> {
Ok(std::f64::consts::PI * self.radius * self.radius)
}
}
#[derive(Clone, CustomInputType, CustomOutputType)]
pub enum Shape {
Rectangle(Rectangle),
Circle(Circle),
Triangle(Triangle),
}
After registering as complex_custom_outputs, they will appear like below in the GraphQL schema:
union Shape = Rectangle | Circle | Triangle
type Rectangle {
origin: Point!
size: Size!
area: Float! # ⬅ as a 'computed property'
}
The area method will only be invoked when a query includes this field. Note that it is an async function, so you can even do database queries inside the function. For example, you can return a SimpleObject from a related model.
The union type definition allows you to use union types in input / output, a very natural construct in Rust.
Full example can be found here.
Lifecycle hooks
In Seaography, all logic is centralized in the same process, and it allows you to inject arbitrary custom logic throughout the request lifecycle using hooks. You can even implement access control this way.
Fine‑grained Access Control
Imagine you have a drawing app, and users can only access projects they own. You can implement the access control logic like the following:
struct AccessControlHook;
impl LifecycleHooksInterface for AccessControlHook {
fn entity_filter(
&self,
ctx: &ResolverContext,
entity: &str,
_action: OperationType, // ⬅ Read, Create, Update, Delete
) -> Option<Condition> {
let session = ctx.data::<Session>()?;
// ⬆ extract user session
match entity {
"Project" => Some(
Condition::all()
.add(project::Column::OwnerId.eq(session.user_id))
// ⬆ add custom filter condition
),
_ => None,
}
}
}
By registering that into Seaography, this function will be called every time an Entity is being accessed:
lazy_static::lazy_static! {
static ref CONTEXT : BuilderContext = {
BuilderContext {
hooks: LifecycleHooks::new(AccessControlHook),
..Default::default()
}
};
}
Other hooks
There are many useful hooks for type conversion, access guard, event notification, etc.
pub trait LifecycleHooksInterface: Send + Sync {
/// This happens before an Entity is accessed
fn entity_guard(
&self, ctx: &ResolverContext, entity: &str, action: OperationType
) -> GuardAction {
GuardAction::Allow
}
/// This happens after an Entity is mutated
async fn entity_watch(
&self, ctx: &ResolverContext, entity: &str, action: OperationType
) {}
}
🖥️ SeaORM Pro: A Seaography Showcase
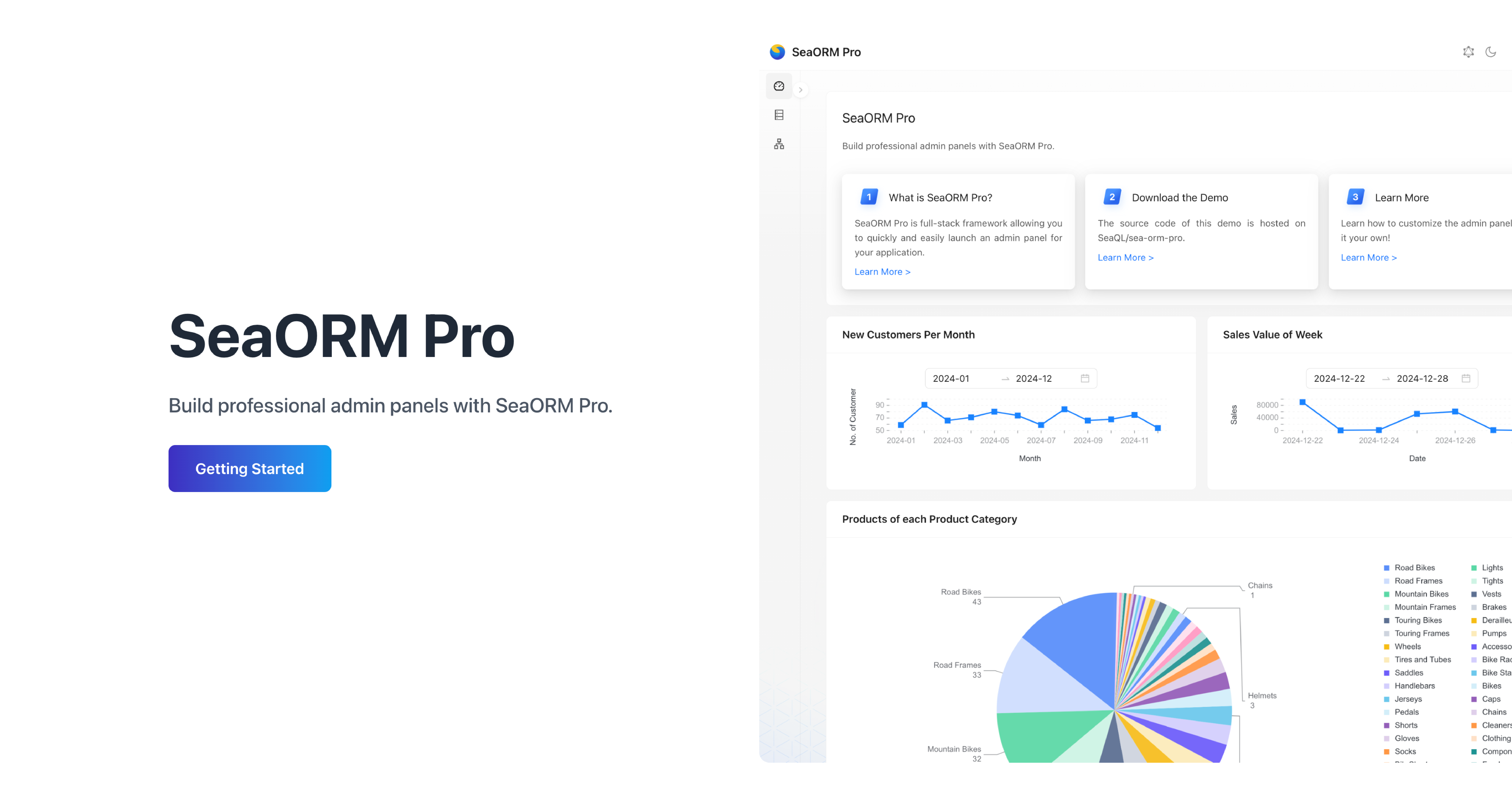
With SeaORM Pro, you can launch a ready-to-use admin panel in minutes. Built on Seaography, it demonstrates the seamless integration of the full technology stack - async Rust backend, React frontend, and GraphQL as the protocol.
SeaORM Pro has been updated to support the latest features in SeaORM 2.0, with RBAC support now available for preview in SeaORM Pro Plus.
Features:
- Full CRUD
- Built on React + GraphQL
- Customize the UI with TOML config
- GraphQL resolver using Seaography
- Custom GraphQL endpoints (new in 2.0)
- Role Based Access Control (new in 2.0)
Conclusion
It took us a long time to get here, but this is our vision for application development in Rust: a framework that makes it effortless to get started, gives developers a ton of functionality out of the box, and still provides the power and flexibility to build complex applications.
We're heavily inspired by tools in the Python, Ruby and node.js ecosystem. You can draw some parallels between Seaography and FastAPI:
| Seaography | FastAPI |
|---|---|
| GraphQL API | Rest API |
| GraphQL schema | JSON Schema |
| GraphQL Playground | Swagger UI |
| Rust native types | Pydantic |
| SeaORM | SQLModel |
In another sense, Seaography is like PostGraphile, offering instant GraphQL API for SQL databases:
| Seaography | PostGraphile |
|---|---|
| MySQL, Postgres, SQLite, SQL Server* | Postgres |
| Compiled schema | Runtime generated schema |
| SeaORM's RBAC | Postgres' RLS |
| Lifecycle hooks, builder context | Plugins |
Sponsors
This Seaography release has been made possible through the generous sponsorship of QDX and their close collaboration with SeaQL.org. QDX has built their data-driven applications with the Seaography + SeaORM stack, and we are deeply grateful for their contributions - both financial and technical - that helped bring this release to reality.
We welcome companies to collaborate with SeaQL.org to adopt and unlock the full potential of the Rust + SeaQL ecosystem, with our team providing expert technical consulting to support their software development.
Gold Sponsor

QDX pioneers quantum dynamics–powered drug discovery, leveraging AI and supercomputing to accelerate molecular modeling. We're grateful to QDX for sponsoring SeaQL.org.