In our last post, we introduced a Smart Entity Loader that made querying multi-path relations into nested models simple and efficient. That solved the read side of the problem.
With nested ActiveModel, you can now do the reverse: persist a nested object back into the database in one operation. SeaORM walks the tree, detects changes, constructs the insert and update statements, and executes them in the correct order to respect foreign key dependencies.
Gist
The following operation saves a new set of user + profile + post + tag + post_tag into the database atomically:
let user = user::ActiveModel::builder()
.set_name("Bob")
.set_email("bob@sea-ql.org")
.set_profile(profile::ActiveModel::builder().set_picture("image.jpg"))
.add_post(
post::ActiveModel::builder()
.set_title("Nice weather")
.add_tag(tag::ActiveModel::builder().set_tag("sunny")),
)
.save(db)
.await?;
Unfolding
This builder pattern constructs the following object tree:
user::ActiveModelEx {
name: Set("Bob".into()),
email: Set("bob@sea-ql.org".into()),
profile: HasOneModel::Set(profile::ActiveModelEx {
picture: Set("image.jpg".into()),
..Default::default()
}),
posts: HasManyModel::Append(post::ActiveModelEx {
title: Set("Nice weather".into()),
tags: HasManyModel::Append(tag::ActiveModel {
tag: Set("sunny".into()),
..Default::default()
}),
..Default::default()
}),
..Default::default()
}
.save(db)
.await?
.. which is equivalent to doing the following manually:
let txn = db.begin().await?;
let user = user::ActiveModelEx {
name: Set("Bob".into()),
email: Set("bob@sea-ql.org".into()),
..Default::default()
}.insert(&txn).await?;
let profile = profile::ActiveModelEx {
user_id: Set(user.id),
picture: Set("image.jpg".into()),
..Default::default()
}.insert(&txn).await?;
let post = post::ActiveModelEx {
user_id: Set(user.id),
title: Set("Nice weather".into()),
..Default::default()
}.insert(&txn).await?;
let tag = tag::ActiveModel {
tag: Set("sunny".into()),
..Default::default()
}
.insert(&txn)
.await?;
post_tag::ActiveModel {
post_id: Set(post.id),
tag_id: Set(tag.id),
}
.insert(&txn)
.await?;
txn.commit().await?;
Relational Dependency
The core of the problem lies in figuring the foreign key relations between Entities and executing the queries in the correct order. SeaORM supports the following:
Has One / Belongs To
User 1-1 Profile
user.rs
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "user")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
#[sea_orm(has_one)]
pub profile: HasOne<super::profile::Entity>,
..
}
There is a unique key on user_id, making this relation one-to-one.
profile.rs
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "profile")]
pub struct Model {
#[sea_orm(unique)]
pub user_id: i32,
#[sea_orm(belongs_to, from = "user_id", to = "id")]
pub user: HasOne<super::user::Entity>,
..
}
Since profile belongs to user, the user has to be inserted first to obtain it's id.
In SeaORM, it doesn't matter which way the model is nested, it will be executed in the correct order.
profile::ActiveModel::builder()
.set_user(
user::ActiveModel::builder()
.set_name("Alice")
.set_email("alice@rust-lang.org"),
)
.set_picture("image.jpg")
.save(db)
.await?;
Has Many
User 1-N Post
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "post")]
pub struct Model {
pub user_id: i32,
#[sea_orm(belongs_to, from = "user_id", to = "id")]
pub author: HasOne<super::user::Entity>,
..
}
This is very similar to 1-1, with the nested model being a vector instead of option.
There are two possible actions: Replace and Append. The default action is append, which is non-destructive.
Let's say Bob has written a new blog post, there is no reason having to query all posts bob has written; we can simply do the following:
let bob = user::Entity::load().filter_by_email("bob@sea-ql.org").one(db).await?.unwrap();
let mut bob.into_active_model();
bob.posts.push(post::ActiveModel::builder().set_title("Another weekend"));
bob.save(db).await?;
However, sometimes we do want an empty vector to mean 'delete all', or we want to specify the exact set of children. Then we can use Replace.
bob.posts.replace_all([]);
bob.posts.replace_all([post_1]);
This will result in the following actions, where posts other than post 1 will be deleted:
SELECT FROM post WHERE user_id = bob.id
DELETE FROM post WHERE id = 2
Many to Many
Post M-N Tag
Many-to-many relations are essential when modeling complex schemas. A unique feature of SeaORM is that it models many-to-many relations as a first-class construct, so you don't need to think about the junction table.
post.rs
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "post")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub title: String,
#[sea_orm(has_many, via = "post_tag")]
pub tags: HasMany<super::tag::Entity>,
..
}
post_tag.rs
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, DeriveEntityModel, Eq)]
#[sea_orm(table_name = "post_tag")]
pub struct Model {
#[sea_orm(primary_key, auto_increment = false)]
pub post_id: i32,
#[sea_orm(primary_key, auto_increment = false)]
pub tag_id: i32,
#[sea_orm(belongs_to, from = "post_id", to = "id")]
pub post: Option<super::post::Entity>,
#[sea_orm(belongs_to, from = "tag_id", to = "id")]
pub tag: Option<super::tag::Entity>,
}
tag.rs
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "tag")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
#[sea_orm(unique)]
pub tag: String,
}
M-N relations is not just 1-N + 1-1, it actually breaks away from the notion. Let's look at the following example, insert a new post with 2 tags:
let sunny = tag::ActiveModel::builder().set_tag("sunny").save(db).await?;
let post = post::ActiveModel::builder()
.set_title("A sunny day")
.set_user(bob)
.add_tag(sunny)
.add_tag(tag::ActiveModel::builder().set_tag("outdoor"))
.save(db)
.await?;
Which results in the following actions:
INSERT INTO post (user_id, title) VALUES (bob.id, 'A sunny day') RETURNING id
INSERT INTO tag (tag) VALUES ('outdoor') RETURNING id
INSERT INTO post_tag (post_id, tag_id) VALUES (post.id, sunny.id) (post.id, outdoor.id)
Their relation is no longer "belongs to", they are just associated with each other.
Removing tags from post does not delete the tags, but only the associations in the junction table.
post.tags.replace_all([outdoor]);
Results in:
DELETE FROM post_tag WHERE (post_id, tag_id) IN ((post.id, sunny.id))
One more example to make this easier to grasp: in a Film M-N Actor relation, deleting a film does not delete its actors, since they can still appear in other films.
Note
SeaORM also supports using a surrogate primary key on the junction table, though a composite primary key is recommended.
film_actor.rs
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "film_actor")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
#[sea_orm(unique_key = "film_actor")]
pub film_id: i32,
#[sea_orm(unique_key = "film_actor")]
pub actor_id: i32,
#[sea_orm(belongs_to, from = "film_id", to = "id")]
pub film: HasOne<super::film::Entity>,
#[sea_orm(belongs_to, from = "actor_id", to = "id")]
pub actor: HasOne<super::actor::Entity>,
}
Change Detection
Let's go back to the basics, in SeaORM every Model is backed by an ActiveModel:
post.rs
pub struct ModelEx {
#[sea_orm(primary_key)]
pub id: i32,
pub user_id: i32,
pub title: String,
pub author: HasOne<super::user::Entity>,
pub tags: HasMany<super::tag::Entity>,
}
pub struct ActiveModelEx {
#[sea_orm(primary_key)]
pub id: ActiveValue<i32>,
pub user_id: ActiveValue<i32>,
pub title: ActiveValue<String>,
pub author: HasOneModel<super::user::Entity>,
pub tags: HasManyModel<super::tag::Entity>,
}
Each ActiveValue is a tri-state.
pub enum ActiveValue<V>
{
Set(V),
Unchanged(V),
NotSet,
}
This allows SeaORM to keep track of what's changed. When you first query a fresh Model from database, the default state is Unchanged. When you perform some change in code, the state will be changed to Set. So when you run save, only the changed columns are updated.
let post = post::Entity::find_by_id(22).one(db).await?.unwrap();
let mut post = post.into_active_model();
post.title = Set("The weather changed!");
post.save(db).await?;
This has two advantages: it avoids over-updating, reducing the amount of data sent over the wire. More importantly, multiple API endpoints can safely update different column sets without risk of race conditions and without relying on transactions or locking mechanisms.
This concept is extended to nested ActiveModels, allowing SeaORM to walk the nested object tree and determine which sub-tree has been changed and requires updating.
For example:
let mut bob: user::ActiveModel = ..;
bob.posts[0].title = Set("Lorem ipsum dolor sit amet".into());
bob.posts[0].comments[0].comment = Set("nice post! I learnt a lot".into());
bob.posts[1].comments.push(
comment::ActiveModel::builder().set_comment("interesting!")
);
bob.save(db).await?;
Results in:
BEGIN TRANSACTION
UPDATE post SET title = '..' WHERE id = post.id
UPDATE comment SET comment = '..' WHERE id = comment.id
INSERT INTO comment (post_id, comment) VALUES (post.id. '..')
COMMIT
It's a lot to take in, but once you build a clear mental model of SeaORM's concepts and mechanisms, you'll find yourself far more productive!
You can find all the techniques described in this blog post in a single-file example application.
Cascade Delete
If the relations are defined with ON DELETE CASCADE, this problem does not exist. However, SeaORM can also perform cascade deletes on the client side. It applies the same rules described above, but in reverse.
For example, Post belongs to User. All posts must be deleted before the user; otherwise, the SQL operation will fail.
let user_4 = user::Entity::find_by_id(4).one(db).await?.unwrap();
user_4.cascade_delete(db).await?;
user_4.into_ex().delete(db).await?;
SELECT FROM profile INNER JOIN user ON user.id = profile.user_id WHERE user.id = 4 LIMIT 1
DELETE FROM profile WHERE profile.id = 2
SELECT FROM post INNER JOIN user ON user.id = post.user_id WHERE user.id = 4
SELECT FROM comment INNER JOIN post ON post.id = comment.post_id WHERE post.id = 7
DELETE FROM comment WHERE comment.id = 5
SELECT FROM post_tag INNER JOIN post ON post_tag.post_id = post.id WHERE post.id = 7
DELETE FROM post_tag WHERE (post_id, tag_id) IN ((7, 2), (7, 3), (7, 4))
DELETE FROM post WHERE post.id = 7
DELETE FROM user WHERE user.id = 4
Weak Belongs To
There is one more special case of the Belongs To relation not yet mentioned: weak 1-N associations, where an entity may have an owner, but is not strictly required.
To give an example, Post 1-N Attachment. However users can upload attachments before drafting posts, thus some attachments may have no associated posts.
attachment.rs
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "attachment")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub post_id: Option<i32>,
pub file: String,
#[sea_orm(belongs_to, from = "post_id", to = "id")]
pub post: HasOne<super::post::Entity>,
}
let post_1 = post::Entity::find_by_id(1).one(db).await?.unwrap();
post_1.cascade_delete(db).await?;
let attachment_2 = attachment::Entity::find_by_id(2).one(db).await?.unwrap();
assert!(attachment_2.post_id.is_none());
Idempotence
The general rule of thumb is idempotence: saving an ActiveModel a second time should be a no-op.
Unless you use replace or delete, no delete will be executed.
let post = post.save(db).await?;
let post = post.save(db).await?;
The ActiveModel you provides is a snapshot of the desired final state of the data, and SeaORM should ensure that it ends up that way. This can be complicated, so please report any bugs.
Tips
Keeping track of whether to use insert or update can be hard, unless the intended action is "create new from scratch". Use save as the default, and let SeaORM decide when to execute insert or update.
(If you already find these concepts familiar, it's no surprise that it's called ActiveModel.)
Backwards Compatibility
All the 2.0 features introduced in this post are fully backwards compatible with 1.0, since only new types and methods have been added: ActiveModelEx, HasOneModel, HasManyModel and a few methods. ActiveModel continues to behave exactly as before.
However, due to the macros needing the relations' attributes to generate the implementations, these features are only available to #[sea_orm::model], but not #[sea_orm::compact_model].
🧭 Instant GraphQL API
With Seaography, the Entities you wrote can instantly be exposed as a GraphQL schema, with full CRUD, filtering and pagination. No extra macros, no Entity re-generation is needed!
With SeaORM and Seaography, you can prototype quickly and stay in the flow. The Entity:
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "user")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub name: String,
#[sea_orm(unique)]
pub email: String,
#[sea_orm(has_one)]
pub profile: HasOne<super::profile::Entity>,
#[sea_orm(has_many)]
pub posts: HasMany<super::post::Entity>,
}
Instantly turned into a GraphQL type:
type User {
id: Int!
name: String!
email: String!
profile: Profile
post(
filters: PostFilterInput
orderBy: PostOrderInput
pagination: PaginationInput
): PostConnection!
}
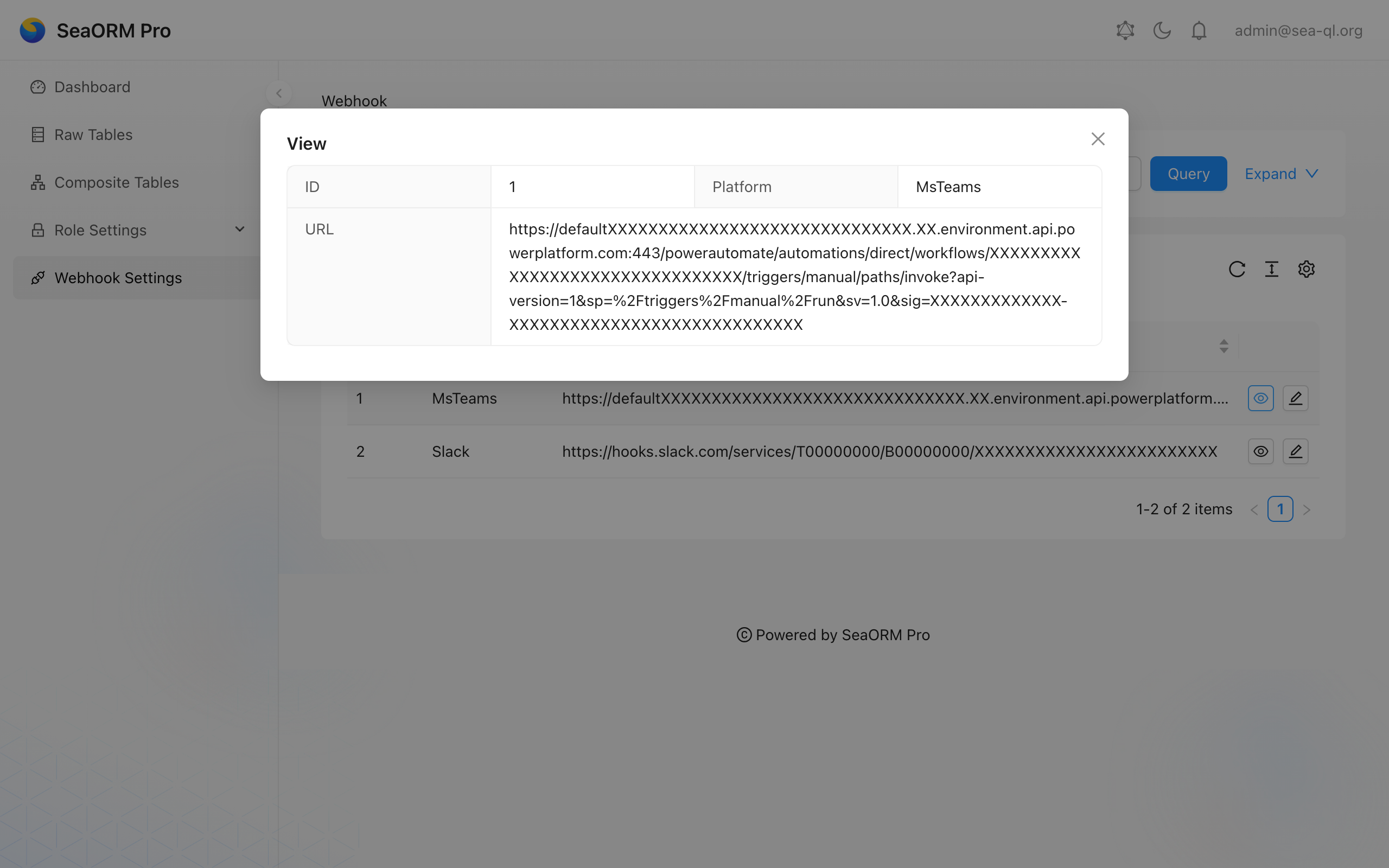
🖥️ SeaORM Pro: Admin Panel
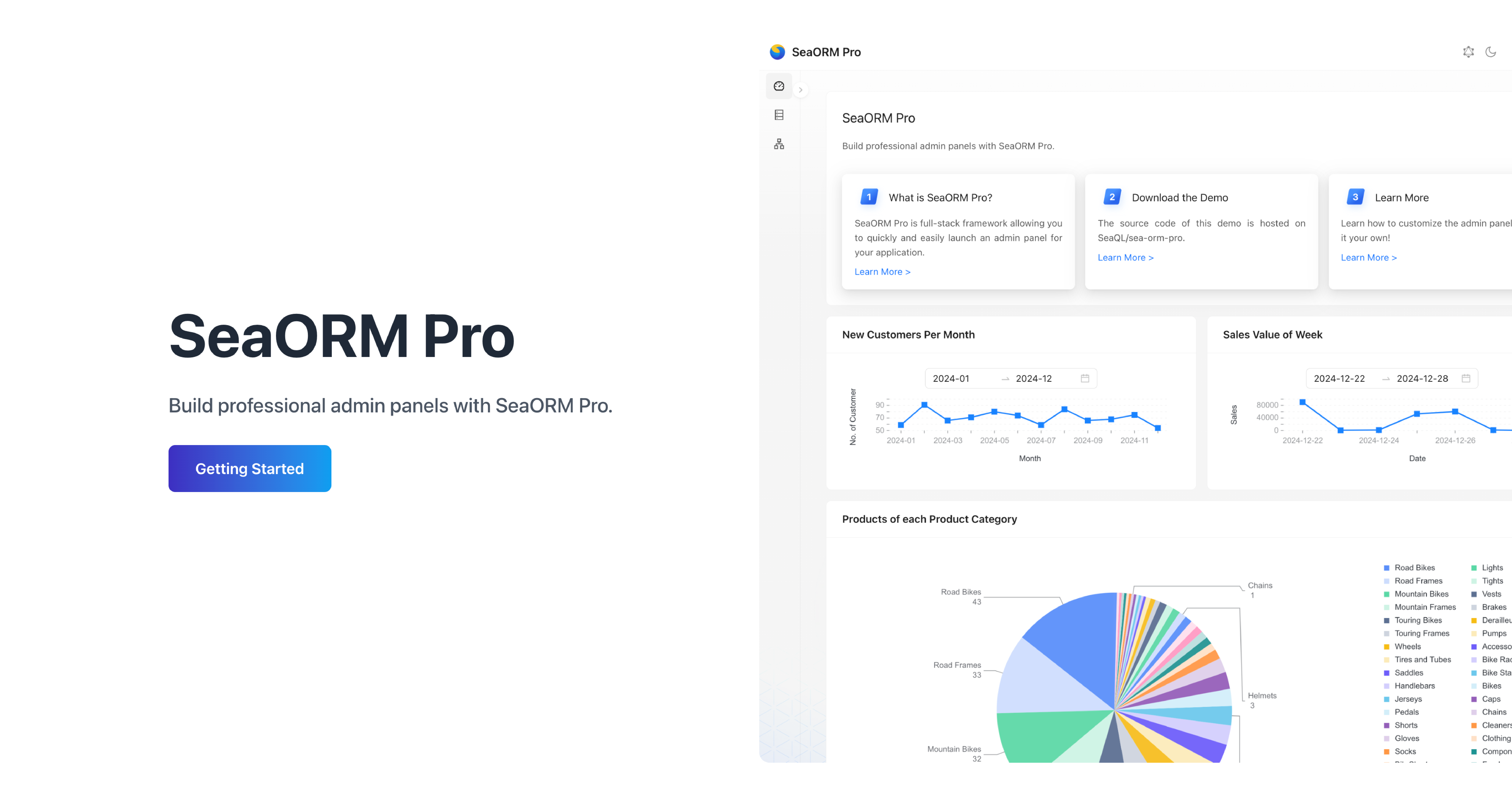
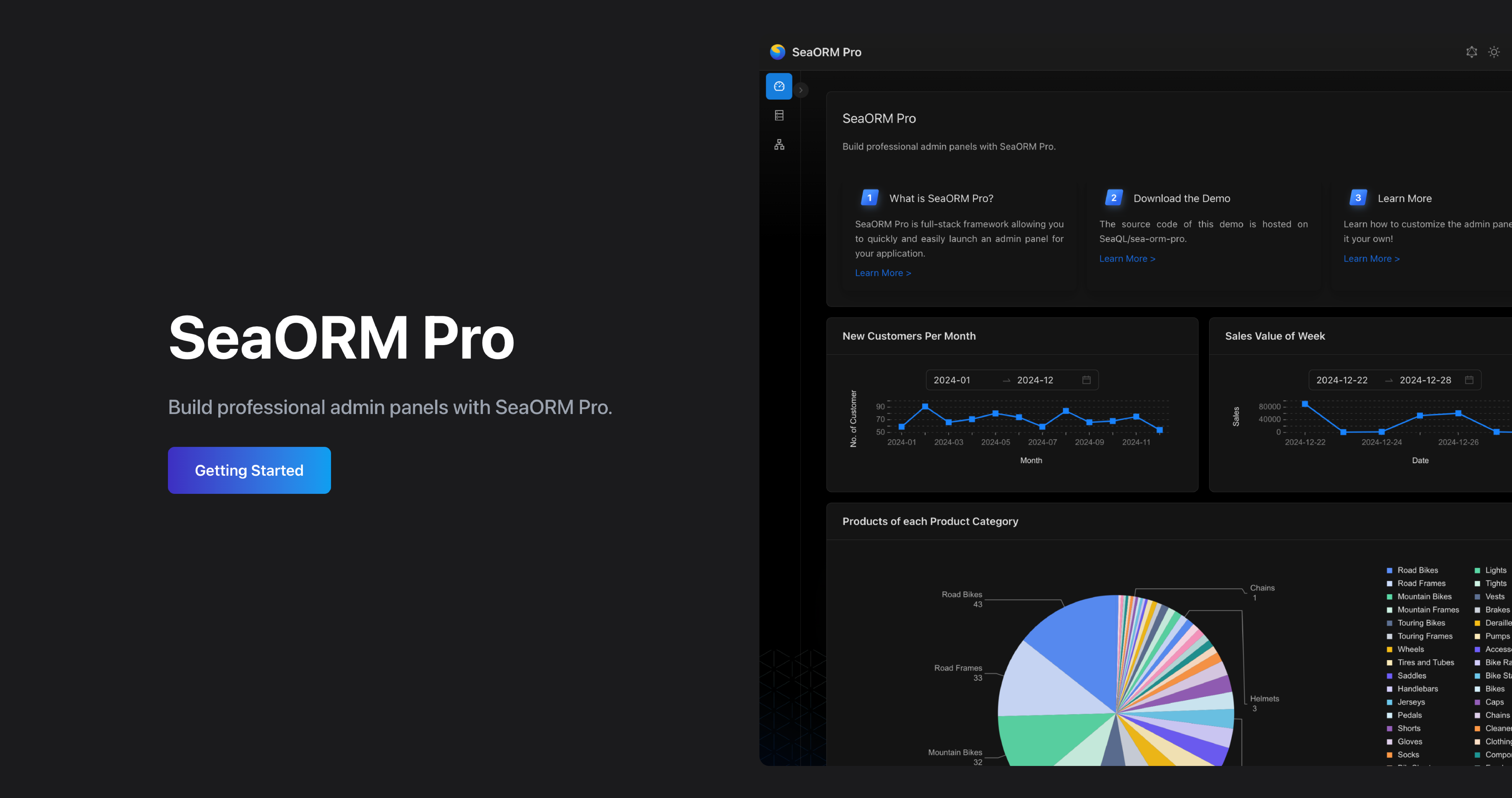
SeaORM Pro is an admin panel solution allowing you to quickly and easily launch an admin panel for your application - frontend development skills not required, but certainly nice to have!
SeaORM Pro has been updated to support the latest features in SeaORM 2.0.
Features:
- Full CRUD
- Built on React + GraphQL
- Built-in GraphQL resolver
- Customize the UI with TOML config
- Role Based Access Control (new in 2.0)

QDX pioneers quantum dynamics-powered drug discovery, leveraging AI and supercomputing to accelerate molecular modeling.
We're grateful to QDX for sponsoring the development of SeaORM, the SQL toolkit that powers their data intensive applications.
If you feel generous, a small donation will be greatly appreciated, and goes a long way towards sustaining the organization.
A big shout out to our GitHub sponsors:
🦀 Rustacean Sticker Pack
The Rustacean Sticker Pack is the perfect way to express your passion for Rust.
Our stickers are made with a premium water-resistant vinyl with a unique matte finish.
Sticker Pack Contents:
- Logo of SeaQL projects: SeaQL, SeaORM, SeaQuery, Seaography
- Mascots: Ferris the Crab x 3, Terres the Hermit Crab
- The Rustacean wordmark
Support SeaQL and get a Sticker Pack!