SeaORM 2.0: New Entity Format


SeaORM’s current entity format is explicit, but it can feel verbose, making it difficult to write by hand. In SeaORM 2.0, we’re introducing a more information‑dense entity format, along with new features that make relational queries easier and more powerful.
Gist
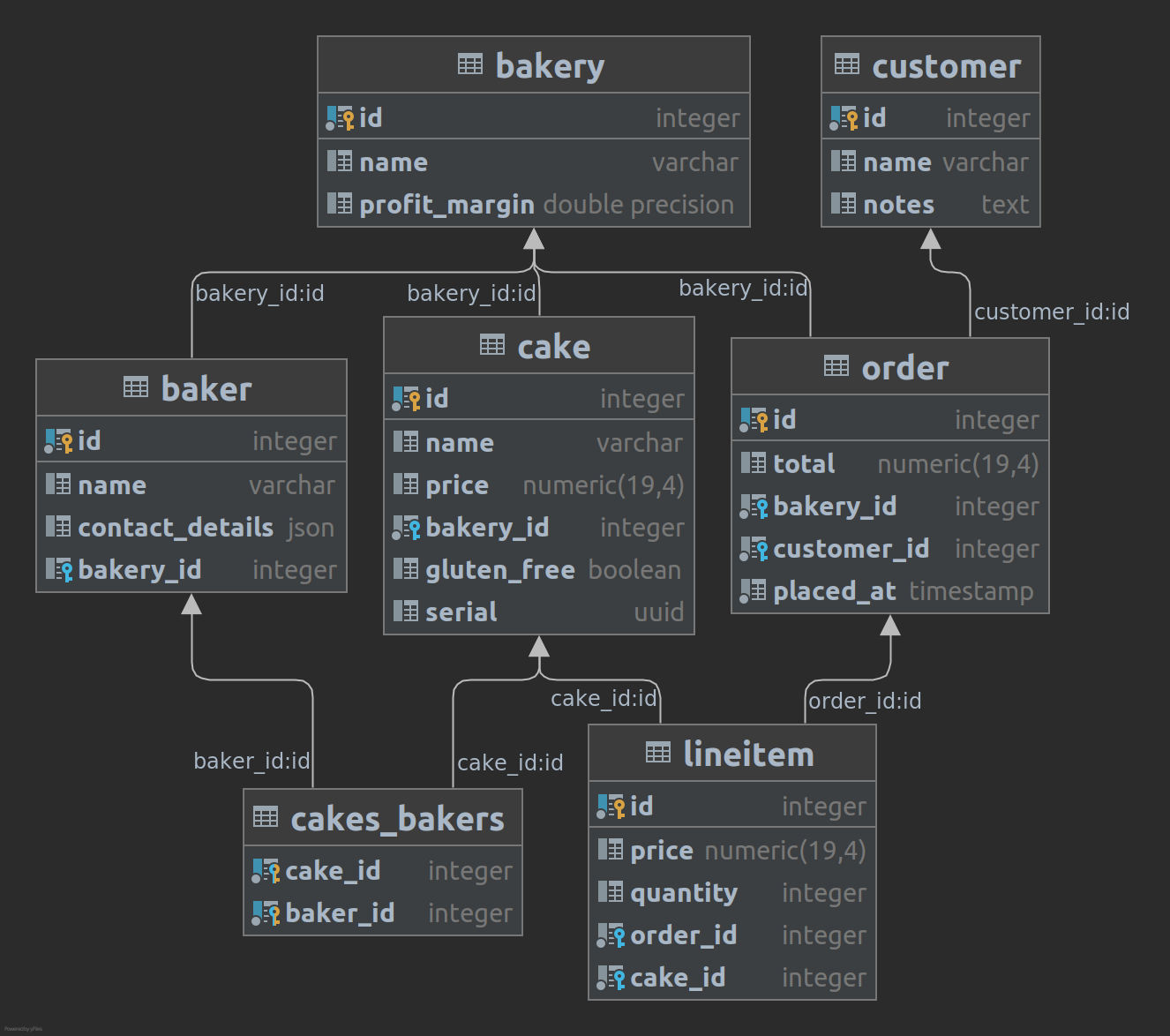
Suppose now we're making a blogging platform. We're designing a simple schema starting from users.
user 1-1 profile
user 1-N post
post 1-N comment
Defining the user Entity as follows:
use sea_orm::entity::prelude::*;
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "user")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub name: String,
#[sea_orm(unique)]
pub email: String,
#[sea_orm(has_one)]
pub profile: HasOne<super::profile::Entity>,
#[sea_orm(has_many)]
pub posts: HasMany<super::post::Entity>,
}
impl ActiveModelBehavior for ActiveModel {}
You will be able to query a user with their profile along with all their blog posts in one operation:
// join paths:
// user -> profile
// user -> post -> comment
let user: Option<user::ModelEx> = user::Entity::load()
.filter_by_id(12)
.with(profile::Entity)
.with((post::Entity, comment::Entity))
.one(db)
.await?;
// has the following shape:
assert_eq!(user.unwrap(), user::ModelEx {
id: 12,
name: "Bob".into(),
email: "bob@sea-ql.org".into(),
profile: HasOne::Loaded(profile::ModelEx {
..
}),
posts: HasMany::Loaded(vec![
post::ModelEx {
title: "Nice day for a walk",
comments: vec![comment::ModelEx { .. }, .. ],
},
post::ModelEx { .. },
]),
});
Full example can be found here.
The Schema
The definition of the user Entity is already shown above, let's look at profile and post:
use sea_orm::entity::prelude::*;
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "profile")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub picture: String,
#[sea_orm(unique)]
pub user_id: i32,
#[sea_orm(belongs_to, from = "user_id", to = "id")]
pub user: HasOne<super::user::Entity>,
}
impl ActiveModelBehavior for ActiveModel {}
profile has a foreign key user_id -> user.id relating back to the user table. By applying a unique constraint, we're effectively making the relation 1-1.
use sea_orm::entity::prelude::*;
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "post")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub user_id: i32,
pub title: String,
pub body: String,
#[sea_orm(belongs_to, from = "user_id", to = "id")]
pub author: HasOne<super::user::Entity>,
#[sea_orm(has_many)]
pub comments: HasMany<super::comment::Entity>,
}
impl ActiveModelBehavior for ActiveModel {}
Similarly, post has a foreign key to the user table, but without the unique constraint. The comment entity is very similar.
use sea_orm::entity::prelude::*;
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "comment")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub comment: String,
pub post_id: i32,
#[sea_orm(belongs_to, from = "post_id", to = "id")]
pub post: HasOne<super::post::Entity>,
}
impl ActiveModelBehavior for ActiveModel {}
Under the hood
It looks clean right? But what magic is going on under the hood? Let's break it down step by step, at the end it actally expands into the current entity format. Such that this new entity format is perfectly backwards-compatible.
A bit of history
In the early days of SeaORM, language servers didn't have very strong macro expansion capabilities. As such, types generated by derive macros can't be seen and picked up by IDEs for auto-completion. That's why in that era crates would prefer to be macro-light, it's also the reason SeaORM (still) has an expanded entity format. The current compact entity format expands into the expanded entity format.
Generating the Relation enum and Related impl
An existing SeaORM entity has three sections, Model, Relation and ActiveModel.
use sea_orm::entity::prelude::*;
pub struct Model { .. }
pub enum Relation { .. }
impl Related<> for Entity {}
impl ActiveModelBehavior for ActiveModel {}
We've hid the Relation / Related section into the Model itself.
For the user entity, a Relation enum is generated:
pub enum Relation {
#[sea_orm(has_one = "super::profile::Entity")]
Profile,
#[sea_orm(has_many = "super::post::Entity")]
Post,
}
In addition, some Related impls are also generated:
impl Related<super::profile::Entity> for Entity {
fn to() -> RelationDef {
Relation::Profile.def()
}
}
impl Related<super::post::Entity> for Entity {
fn to() -> RelationDef {
Relation::Post.def()
}
}
For the profile entity, it gets slightly more elaborate:
pub enum Relation {
#[sea_orm(
belongs_to = "super::user::Entity",
from = "Column::UserId",
to = "super::user::Column::Id"
)]
User,
}
impl Related<super::user::Entity> for Entity {
fn to() -> RelationDef {
Relation::User.def()
}
}
Generating the Model
Note that the Model is now not 'plain-old', as it has some nested fields:
pub struct Model {
pub id: i32,
pub name: String,
pub email: String,
pub profile: HasOne<super::profile::Entity>, // <-
pub posts: HasMany<super::post::Entity>, // <-
}
We have to drop these fields to make the struct simple, such that we can still do the following:
let user = user::Model { id: 1, name: "Bob".into(), email: "bob@sea-ql.org" };
That's why as you may have noticed, we need an attribute macro:
#[sea_orm::model]
We call the compound Model with nested fields ModelEx. May be it can have a better name, but you should rarely need to name this type explicitly.
More relation types
What makes SeaORM stand-apart is that we support many different kinds of relations in real-world complex schemas. Many users may never encounter them, but they're there when you need them.
Many to many relation with junction table
SeaORM is unique in its ability to model many‑to‑many relations as first‑class constructs. Most APIs treat both 1-N and M-N synonymously, and you never need to manually specify the junction table when writing queries.
Let's say post M-N tag, all you need is to specify the junction with the via attribute:
mod post {
use sea_orm::entity::prelude::*;
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "post")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
#[sea_orm(has_many, via = "post_tag")]
pub tags: HasMany<super::tag::Entity>,
}
impl ActiveModelBehavior for ActiveModel {}
}
This is the junction table:
mod post_tag {
use sea_orm::entity::prelude::*;
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, DeriveEntityModel, Eq)]
#[sea_orm(table_name = "post_tag")]
pub struct Model {
#[sea_orm(primary_key, auto_increment = false)]
pub post_id: i32,
#[sea_orm(primary_key, auto_increment = false)]
pub tag_id: i32,
#[sea_orm(belongs_to, from = "post_id", to = "id")]
pub post: Option<super::post::Entity>,
#[sea_orm(belongs_to, from = "tag_id", to = "id")]
pub tag: Option<super::tag::Entity>,
}
impl ActiveModelBehavior for ActiveModel {}
}
To query posts with tags, you call the exact same method, without even mentioning the junction.
let posts = post::Entity::load().with(tag::Entity).all(db).await?;
assert_eq!(posts, vec![post::ModelEx {
tags: vec![ tag::ModelEx { .. }, .. ]
}]);
// or you can use the model loader API:
let posts: Vec<post::Model> = post::Entity::find().all(db).await?;
let tags: Vec<tag::Model> = posts.load_many(tag::Entity, db).await?;
Self-referencing relations
#[sea_orm::model]
#[derive(Clone, Debug, PartialEq, DeriveEntityModel, Eq)]
#[sea_orm(table_name = "staff")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub name: String,
pub manager_id: i32,
#[sea_orm(
self_ref,
relation_enum = "Manager",
from = "manager_id",
to = "id"
)]
pub manager: HasOne<Entity>,
}
The generated enum will have a variant like:
pub enum Relation {
#[sea_orm(
belongs_to = "Entity",
from = "Column::ManagerId",
to = "Column::Id",
)]
Manager, // <- relation_enum
}
This aspect is not so different from 1.0. A Related impl will not be generated, but the relation can still be used in loader or join queries.
Composite foreign key
You don't use it very often, but SeaORM actually supports it since 0.1. Some lines are omitted for brevity.
mod composite_a {
#[sea_orm::model]
#[sea_orm(table_name = "composite_a")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
#[sea_orm(unique_key = "pair")] // <- name this unique key
pub left_id: i32,
#[sea_orm(unique_key = "pair")]
pub right_id: i32,
#[sea_orm(has_one)]
pub b: Option<super::composite_b::Entity>,
}
}
mod composite_b {
#[sea_orm::model]
#[sea_orm(table_name = "composite_b")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub left_id: i32,
pub right_id: i32,
#[sea_orm(
belongs_to,
from = "(left_id, right_id)",
to = "(left_id, right_id)"
)]
pub a: Option<super::composite_a::Entity>,
}
}
Designing an ORM that can support all these scenario is hard with exploding complexities, but this is exactly what makes SeaORM powerful and sets it apart. Even if you don’t need these features today, choosing SeaORM helps ensure your application is future-proof.
New find/filter by unique key methods
To improve ergonomics, SeaORM 2.0 now automatically generates type-safe shorthand methods for unique keys:
user::Entity::find_by_email("bob@sea-ql.org").one(db).await?
user::Entity::load().filter_by_email("bob@sea-ql.org").one(db).await?
It even works on composite unique keys!
// the name `pair` is user-defined above
composite_a::Entity::find_by_pair((1, 2)).one(db).await?
composite_a::Entity::load().filter_by_pair((2, 3)).one(db).await?
(Smart) Entity Loader
We've spent a lot of engineering effort in designing the new Entity Loader. You can see it as magic, because it eliminates the N+1 problem even when doing nested queries while preventing over-fetching at the same time.
In the nested query we shown you in the beginning, 3 queries are executed:
SELECT FROM user JOIN profile WHERE id = $
SELECT FROM post JOIN user WHERE user_id IN (..)
SELECT FROM comment WHERE post_id IN (..)
For 1-1 relations, it does a join and select up to three tables together in a single query.
For 1-N or M-N relations, it uses the data loader. Note that, it's a single query even for M-N relation, as the junction table will be joined.
For nested queries, it uses the data loader. It consolidates the id of all the posts in the 2nd query and issue one query for the comments.
Backwards compatibility
The new Entity format is perfectly backwards compatible as it gets expanded into the current compact format. However, the Entity Loader generates a bit of extra code under the hood, and it's not available for compact entities. We've introduced a transitional macro, in case you want to take advantage of the Entity Loader without migrating to the new format.
#[sea_orm::compact_model] // <- add this
#[derive(Clone, Debug, PartialEq, Eq, DeriveEntityModel)]
#[sea_orm(table_name = "post")]
pub struct Model {
#[sea_orm(primary_key)]
pub id: i32,
pub user_id: i32,
pub body: String,
// #[sea_orm(belongs_to, from = "user_id", to = "id")] // <- not needed
pub author: HasOne<super::user::Entity>, // <- add these compound fields
}
// the rest of the Entity file is exactly the same as before
#[derive(Copy, Clone, Debug, EnumIter, DeriveRelation)]
pub enum Relation { .. }
Now you can do:
post::Entity::load().with(super::user::Entity)..
The current compact entity format has more flexibility, as you can:
- add new
Relationenum variants - add
on_conditionon relations
Updated codegen
sea-orm-cli has been updated to generate this new entity format, including with Seaography support. You can run the same entity generate command, but with an additional --entity-format dense flag. We may turn this on by default in the future.
sea-orm-cli generate entity --output-dir ./src/entity --entity-format dense
More to come
SeaORM 2.0 is shaping up to be our most significant release yet - with a few breaking changes, plenty of enhancements, and a clear focus on developer experience. We'll dive into Entity-first workflow in the next post, so keep an eye out for the next update!
SeaORM 2.0 will launch alongside SeaQuery 1.0. If you make extensive use of SeaQuery, we recommend checking out our earlier blog post on SeaQuery 1.0 to get familiar with the changes.
SeaORM 2.0 has reached its release candidate phase. We'd love for you to try it out and help shape the final release by sharing your feedback.
SQL Server Support
SQL Server for SeaORM offers the same SeaORM API for MSSQL. We ported all test cases and examples, complemented by MSSQL specific documentation. If you are building enterprise software, you can request commercial access. It is currently based on SeaORM 1.0, but we will offer free upgrade to existing users when SeaORM 2.0 is finalized.
🖥️ SeaORM Pro: Admin Panel
SeaORM Pro is an admin panel solution allowing you to quickly and easily launch an admin panel for your application - frontend development skills not required, but certainly nice to have!
SeaORM Pro has been updated to support the latest features in SeaORM 2.0.
Features:
- Full CRUD
- Built on React + GraphQL
- Built-in GraphQL resolver
- Customize the UI with TOML config
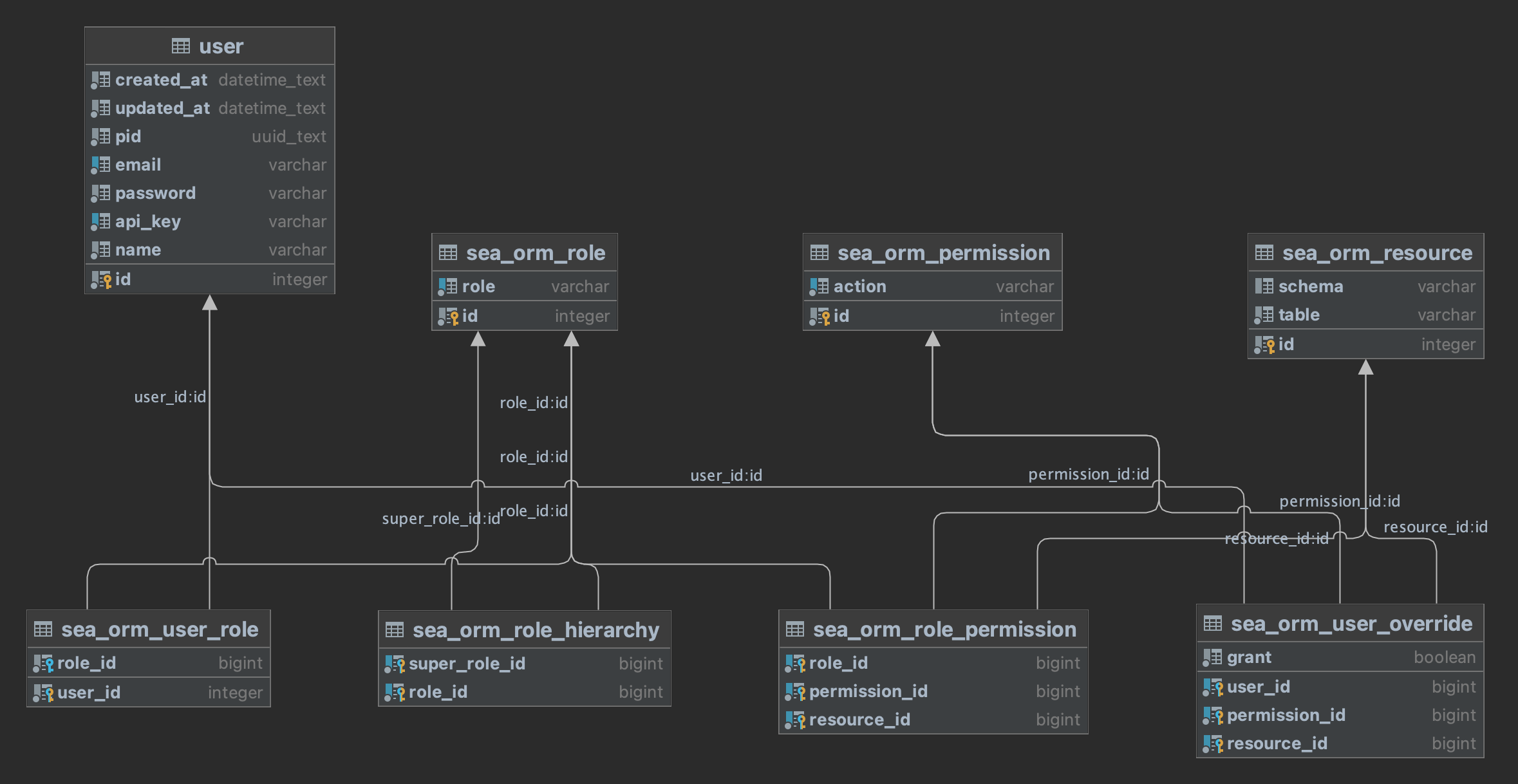
- Role Based Access Control (new in 2.0)
🌟 Sponsors
Gold Sponsor

QDX pioneers quantum dynamics-powered drug discovery, leveraging AI and supercomputing to accelerate molecular modeling. We're grateful to QDX for sponsoring the development of SeaORM, the SQL toolkit that powers their data intensive applications.
GitHub Sponsors
If you feel generous, a small donation will be greatly appreciated, and goes a long way towards sustaining the organization.
A big shout out to our GitHub sponsors:














🦀 Rustacean Sticker Pack
The Rustacean Sticker Pack is the perfect way to express your passion for Rust. Our stickers are made with a premium water-resistant vinyl with a unique matte finish.
Sticker Pack Contents:
- Logo of SeaQL projects: SeaQL, SeaORM, SeaQuery, Seaography
- Mascots: Ferris the Crab x 3, Terres the Hermit Crab
- The Rustacean wordmark
Support SeaQL and get a Sticker Pack!